A conversation with Philipp Diesinger, Partner at Rewire, on what European companies often get wrong when hiring senior data talent, AI readiness, and the cost of moving too slowly.
In this conversation, Matthew Miles, Managing Director at MAM Gruppe speaks with Philipp Diesinger, Partner at Rewire, about the realities of hiring and building data and AI capabilities in European enterprises. Drawing on extensive experience advising leading European companies and transformation programmes, Philipp shares his insights on where organisations misread the talent market, why technical brilliance alone is not enough, and what it takes to build a data function that retains exceptional people.
Matthew Miles: When you scope a data & AI transformation, what is the gap between what a client thinks they need in a hire versus what you see as the capability gap?
Philipp Diesinger: Clients typically ask for technical depth: a strong engineer, a seasoned architect, someone who knows the stack. What they actually need is someone who can translate data capability into business value. The real gap is rarely technical. It is the ability to navigate organizational complexity, build trust with the business, and drive adoption. A brilliant data engineer who cannot get a CFO to act on an insight is not solving the actual problem.
What is the most common misalignment you see between a job spec and the real problem a data leader is being hired to solve?
The job spec describes a builder. The real problem requires a change agent. Companies write specs that read like wish lists for someone who can modernize the stack, implement a platform, and upskill the team simultaneously. But what they actually face is a political and cultural challenge: siloed ownership of data, lack of executive sponsorship, and a business that does not yet see data as an asset. The hire needs to navigate that reality first, before building anything.
| “The job spec describes a builder. The real problem requires a change agent.”
Q: How do you define “data ready”, and how often are their internal hiring briefs aligned to that?
Data ready means three things: governed data that people trust, a business that asks data questions before making decisions, and a leadership team that funds and protects the data function. In my experience, fewer than one in four European company meet all three criteria when they start a transformation. Yet their hiring briefs routinely ask for someone to lead advanced analytics or scale AI. One client was hiring a Head of AI while their core CRM data had no single owner and three conflicting definitions of “active customer.” In that sense the brief was not making explicit the reality of things. And so I go back to the observation made above - about the real problem requiring a change agent rather than a builder.
Q: What is the number one reason you reject candidates for senior Data & AI roles?
First: inability to make the abstract concrete for a non-technical audience. I have interviewed candidates who can design elegant architectures but cannot explain in plain language what value their last project delivered to the business. One senior candidate described a complex ML pipeline in detail but could not tell me what decision it improved or by how much. In a leadership role, that is disqualifying. You are not just building systems. You are building confidence in data across the organisation.
Second: lack of analytical or AI skills. This happens very often with junior candidates fresh out of university.
| “You are not just building systems. You are building confidence in data across the organisation.”
Q: If you had to pick two traits that separate a truly indispensable data professional from one who is replaceable by AI or outsourcing, what are they?
First: contextual judgment. AI can generate analysis; it cannot judge which insight matters most in this company, at this moment, given this leadership team. That requires deep situational awareness that only comes from being present, curious, and politically attuned.
Second: trust building. The professionals who survive every wave of automation are the ones that people turn to when they need to make a hard call. That is a human relationship, not a skill set. It is earned over time and it cannot be outsourced.
Q: You work with clients on AI transformation at scale. What does “business acumen” look like in a data leader who has it versus one who does not?
A data leader with genuine business acumen walks into a conversation about a use case and asks: what decision does this change, who owns that decision, and what would it cost us to get it wrong? They think in terms of risk, margin, and accountability.
A data leader without it asks what data is available and what model could be trained. Both are smart people. But the first one gets budget and the second one gets deprioritised. Business acumen in this context means understanding that every data initiative is ultimately a bet on changing behaviour, not just improving infrastructure.
| “Every data initiative is ultimately a bet on changing behaviour, not just improving infrastructure.”
Q: The “outgoing introvert” — someone who is deep in numbers but can also hold a room with a senior stakeholder. How rare is that profile, in your view?
Genuinely rare. Not impossible, but rare. In a pipeline of 100 strong candidates for a senior data role, I would identify perhaps eight to ten who have both the analytical rigour and the presence to be credible in front of a board or an executive committee. What I find more often are candidates who have learned to fake one side. They present well but lack depth, or they have real depth but are exhausting for non-technical people to follow. The authentic combination, where depth and communication reinforce each other rather than compete, is what makes certain candidates exceptional.
Q: What does a data function look like in a company that retains great people versus one that consistently loses them?
Companies that retain great data talent share a few characteristics. Decisions actually get made using data, so people feel their work has impact. The CDO or data lead has real access to the C-suite, not just a dotted line to the CIO. And there is a visible career path that goes beyond becoming a better technician. Data talent is enabled by leadership.
Companies that lose people tend to treat the data team as a service function: reactive, under-resourced, and perpetually blocked by governance or IT. The best people leave not because of salary but because they stop believing the organisation wants what they are capable of delivering. They stay because of purpose.
| “The best people leave not because of salary but because they stop believing the organisation wants what they are capable of delivering.”
Q: How important is visible AI investment to attracting senior data talent right now?
It is a qualifying criterion, not a differentiator. Senior candidates now expect to see meaningful AI investment before they will engage seriously. What they want to see is not a press release about AI strategy. They want evidence of real use cases in production, a clear data foundation, and leadership that understands what AI actually requires. Companies that are still debating their cloud migration while advertising for a Head of AI will find it very hard to attract credible candidates. The market has moved and expectations have risen sharply in the past 18 months.
Q: If you were advising a Chief Data Officer today, what are the main things you would tell them about the talent market?
First, the pool of senior candidates with both technical credibility and executive presence is small and they are mostly not actively looking. You have to go and find them, which means investing in your employer brand and your network, not just posting a job.
Second, competing on salary alone will not work. The candidates you want have options. They are choosing based on mandate, culture, and whether they believe the organisation is serious about data.
Third, do not underestimate the international dimension. Some of the best candidates may not be based in your country and may not want to relocate full time. If you insist on five days on site, you are filtering out a significant portion of the available talent pool before the first conversation has taken place.
Q: What is the most dangerous assumption European companies are making right now when it comes to data & AI hiring?
That they have time. There is a widespread belief in Europe that AI is something to get right before deploying, and that careful, methodical planning will eventually produce a competitive position. Meanwhile, companies in the US, UK, and parts of Asia are iterating at speed, making mistakes in production, and learning faster. The talent that knows how to move at that pace is being absorbed into organisations that operate that way. By the time a European company has finished its internal approval process for a new data role, the candidate they wanted has accepted an offer elsewhere. Caution is a cultural strength in many contexts. In the current AI talent market, it is becoming a liability.
| “Caution is a cultural strength in many contexts. In the current AI talent market, it is becoming a liability.”
About the participants
Dr. Philipp M. Diesinger is a Partner at Rewire DACH, where he advises enterprise clients on data and AI strategy, transformation, and capability building. Before Rewire, Philipp held roles at BCG and has a PhD in natural sciences.
Matthew Miles leads Technology, Data & AI at MAM Gruppe, a specialist recruitment agency placing -senior professional & leadership roles across Germany’s technology, legal, and finance markets since 2009. Matthew has worked exclusively in the German market for over 15 years.

Building your AI capabilities, end-to-end
From turning Data & AI talent into impactful professionals to delivering tailored executive training, we help your company build the capabilities needed to lead with AI at every level.
Explore our AI strategy servicesThe Mittelstand companies getting AI right treat it as a capability they build and own. The lessons reach far beyond Germany.
The Mittelstand – the dense network of small and medium-sized enterprises widely regarded as one of the defining strengths of the German economy – is built on world-class craft and specialization. Many Mittelstand companies are experimenting with AI. The most successful ones treat it not as a project, but as a capability they build themselves. That way they win twice: operational impact in the short term, independence in the long term. Their experience holds lessons for companies of all sizes — in Germany and beyond.
In many mid‑sized companies today, a similar picture emerges: several AI initiatives run in parallel, often for years, without being successfully absorbed into daily operations. At the same time, every one of these companies has pockets where AI quietly but reliably creates value. The difference between the two rarely lies in the tool, but in the approach.
Companies that generate tangible value with AI rarely have the fastest technology or the largest budget. They have something else: a clear view of where AI truly changes something in their processes, and the discipline to start exactly there.
The decisive question is therefore less “Which AI tool should we buy?” and more: How do we build the capability to integrate AI into our work for the long term and steer it ourselves? Those who answer this question win twice: operational effects visible in the first months, and a resilient independence that pays off year after year.
When AI really delivers in the Mittelstand
Before turning to the typical pitfalls, it is worth looking at what demonstrably works. Out of hundreds of projects, three factors consistently come together in successful AI applications.
First: a clear goal inside the process. Which concrete decision or action should AI make better, faster, or more reliable? “Cut the time from customer enquiry to finished quote in half so that sales can respond faster and with greater accuracy” is a goal teams can tackle immediately. And one against which success can be measured.
Second: the right data, understandable and reliable. The Mittelstand typically has rich operational data from ERP, MES, CRM, lab, and field systems. The leverage appears when the data points relevant to the specific use case are cleanly defined and stably available. That is usually far more focused and reachable than the much‑invoked “data cleanup across the whole company.”
Third: results where the decision is made. For classic operations use cases such as maintenance, quality, or planning, this usually means: directly in the ERP, MES, or CRM, i.e. where people are already working. For agentic applications in sales, procurement, technical support, or medical affairs, by contrast, the point of decision often sits outside the core systems: in the email inbox, the ticketing system, the document repository. Good agentic AI orchestrates those sources, prepares the decision, and flows the result back into the ERP or CRM. The rule is therefore not “always into the core system,” but: wherever the human decides.
Where these three elements come together, impact emerges that is measurable and scalable. That is not theory; it is the pattern behind the most successful AI initiatives we accompany in the Mittelstand.
Beyond the Mittelstand: four patterns that mark successful AI delivery
However different industries and maturity levels may be, companies that are making visible progress with AI attend to the same four themes. Each one is a step closer to the double win of operational impact and independence.
1. Enable the right people, not only the technologists
A common assumption is that AI competence is primarily a matter of additional data scientists. In practice, the larger leverage emerges elsewhere: with the people who truly know processes, customers, and equipment. Process owners, key users, team leads, shop‑floor foremen.
The greatest leverage does not sit in IT, but at the process.
This group brings exactly what makes AI projects take off: context. They know how a manufacturing order moves through the ERP, what sales decides first thing in the morning, and which supplier data can be trusted. When these people are deliberately enabled, in short, practice‑oriented sessions and on real use cases, a technical initiative becomes a working tool.
A typical pattern in practice: Data scientists and the business form joint tandems. Domain knowledge flows into requirements, AI results flow back into the process. The time from idea to first productive version typically halves, without additional tools or additional headcount.
2. Focus on a few, genuinely viable use cases
“We have twenty proofs of concept.” That sounds like momentum, and in the early phase often is. The next step, however, decides whether experiments turn into impact: prioritize clearly, hand over ownership clearly, scale clearly.
Two running use cases beat twenty planned ones.
Successful portfolios in the Mittelstand are deliberately lean: three to five use cases with visible leverage on core processes, each with a named owner and clear success criteria. Equally important is the culture of finishing things. When a pilot has exhausted its potential, or impact fails to materialize, it is deliberately closed and makes room for the next.
An illustrative picture from sales: Mid‑sized industrial equipment suppliers often have an inside sales team that simultaneously handles quote requests, spare‑parts enquiries, and service coordination. Instead of working on many ideas in parallel, successful approaches concentrate on one clearly defined step, for example pre‑qualifying incoming enquiries through an agentic assistant that pulls customer data from the CRM and proposes a first draft offer. The benefit shows up less in a single KPI than in the inside sales team being noticeably relieved and enquiries being answered more consistently.
3. Anchor AI directly where decisions are made
Perhaps the most important lever sits in the “last mile”: how does the AI result reach the person who has to work with it? The companies that are consistent here do not build AI as a separate dashboard, but as a natural part of the workflow.
The “last mile” decides between “AI introduced” and “AI in use.”
In practice: a notification in the existing system rather than an additional interface. Clear accountability for who decides on the basis of the forecast. A defined escalation when the model is uncertain. A “human‑in‑the‑loop” where experience makes the call. AI then becomes not an add‑on, but an extra pair of eyes and hands in daily operations.
An illustrative picture from procurement & supply chain: In technical wholesale, supplier risk is increasingly monitored agentically. An agent scans news, commercial register updates, and logistics data, evaluates changes, and on critical signals creates a task directly in the procurement system, including a recommended action and point of contact. The buyer still decides, as always. But knows sooner where to look.
4. Treat AI as a product, not as a project
This is a shift at first, but not a major hurdle when planned for from the start. Successful companies give their AI systems after launch the same attention they give their products: a responsible owner, an operating concept, regular quality checks, versioning, and cost control.
Software projects have an end. AI systems do not.
The effect is remarkable: the model stays reliable even as inputs or processes change. Trust in the systems grows steadily, and with it the willingness to extend AI into further areas.
A typical pattern in practice: Operating concept and ownership are built into development from the start, not bolted on after going live. Those who do this incur little extra effort. Those who have to add it later pay noticeably more. Experience points to two to three times the original development cost.
Doing AI, not just having AI
The four patterns share one thing: they shift the emphasis from “buying AI” to “doing AI.” And this is exactly where the Mittelstand plays to its strengths: closeness to the process, pragmatism, clear accountability, fast decisions.
Companies that stay ahead with AI build capability: teams that understand and steer AI; data products that are maintained and reliable; systems that run in everyday use, not in the test environment; and an operating logic that secures the value tomorrow as well.
That does not require a corporate apparatus. It requires focus: three to five use cases with real leverage on core processes, the right people behind them, and the decision to treat AI as a capability you develop, rather than a project you finish.
So the arc closes: those who build AI as a core capability win twice. In the short term through operational effects that become measurable in weeks and months: less downtime, faster quotes, sharper decisions. In the long term through an independence that makes them resilient to vendor fashions, market cycles, and the next technology wave. The Mittelstand brings everything needed for this path: depth of craft, closeness to execution, and a culture in which things count as finished only when they are running in operations.
Which of these four themes is currently moving you most in your AI work? We would be happy to exchange views with you, as peers and from the perspective of delivery.
This article was written by Philipp Diesinger, Partner at Rewire. His focus is on AI transformations that make the leap from pilot to productive operations: in life sciences, industry, energy, and the German Mittelstand.
Building your AI capabilities, end-to-end
Our strategies elevate the impact of AI from marginal or tactical to transformational successes.
Explore our AI strategy servicesLessons from industry pioneers building the data foundation for AI agents
Last week, Rewire hosted the third edition of the Data Leadership Roundtables. We gathered a select group of industry pioneers – from retail giants like Albert Heijn and financial leaders like Nexent Bank to biochemical innovators like Corbion – to tackle a pressing question: How do we bridge the gap between fast-moving agentic AI and the scalable rigor of Data Management?


Ontologies talk: coffee is a great way to build relations.
Bridging the gap: context as the universal language
The session opened with a thesis: agentic AI moves fast, but data management scales. The true value lies in the intersection. A shared approach to context and metadata can unify these two worlds. Bridging this gap requires three strategic shifts:
- Investing in new capabilities: Prioritizing Knowledge Graphs and Model Context Protocol (MCP) integration for Data Products.
- Powering AI with trust: Leveraging Data Products to provide AI agents with context built on verified, trusted metadata.
- Democratizing context: Distributing semantics across use cases and domains to ensure AI agents speak the same "business language."

The CDO perspective: data ownership at the source
A highlight of the event was a fireside Q&A with Gabriela Filip (ex-CDO at Knab). Gabriela offered a masterclass in balancing speed with integrity. Her advice: Data ownership must live where the decisions happen.
Key takeaways from her perspective included:
- Local flexibility, global alignment: Keep operational definitions flexible at the local level. Mandate "strong alignment" only for critical, cross-domain business decisions.
- The "Knowledge-First" approach: Combine business and data expertise to effectively capture knowledge, supported by roles like Information Architects and coordinated by leadership (e.g., CDO).


Gabriela Filip and Freek van Gulden sparring over data strategies
Insights from data practitioners: the three recipes for success
Following the plenary, participants broke into deep-dive roundtables covering data governance, operational ownership, and organizational change. Here are some of the "recipes" that emerged:
- Start small, deliver value first: The path to structured governance and knowledge starts by linking data governance to business value. Start with a specific use case, let governance evolve around it, and use visible wins to reduce resistance, drive adoption, and scale.
- Flexibility over rigid architecture: With AI evolving rapidly, the only certainty is that rigid "end-state" architectures will become obsolete before they are even finished. Focus instead on decoupled, modular setups. (For deeper insights, check out this blog post.)
- Connecting defensive with offensive strategies: exploit defensive data management initiatives – like fixing metadata, glossaries – to comply with regulatory compliance. Then use this as an opportunity to create a scalable knowledge foundation that provides a fly-wheel for offensive value creation.


Participants sharing the challenges and lessons learned.
The dialogue doesn't end here
The day’s discussions reaffirmed that navigating today’s Data & AI landscape isn’t just about tools - it’s also a bit about community: Together, we’re better equipped to tackle the complexities and turn challenges into opportunities.
Until the next Roundtable!
Building your data capabilities, end-to-end
Our strategies elevate the performance of your data management from marginal or tactical results to transformational successes.
Explore our data management servicesThree design principles to create a flexible, reusable data architecture that grows with your organization.
You’ve got the prerequisites in place:
- A strategic AI roadmap. Check.
- The ability to develop data products. Check.
- Leadership alignment. Check.
The real question is: How can you build a data foundation that delivers value early without creating long-term problems, such as inconsistent metrics, fragile pipelines and technical debt.
It’s tempting to design the full data foundation upfront. In practice, this often leads to over-engineering, slow delivery, and frustrated stakeholders. A more effective approach is to start from value—while making deliberate design choices that allow the foundation to scale.
Why building a data foundation is so difficult
First, let's be clear about what we mean by a data foundation: A data foundation is the strategic layer of reusable, trusted data products, governance, and architecture that breaks down silos and turns raw data into actionable information aligned with business outcomes.
This enables organizations to accelerate analytics and AI use cases by providing consistent, high-quality data that supports both current needs and future growth. (More on data management fundamentals here.)
Building a data foundation is not just a technical exercise. Yes, you need platforms, pipelines, and integrations. But the real challenge is balancing (1) business impact, (2) trust in data, and (3) long-term scalability. Most organizations struggle because they oscillate between two common approaches to data foundation strategy.
Let's review them.
Top-down vs bottom-up data foundation approaches
Typically, one can consider starting top-down (i.e. from a value pool perspective) or bottom-up (i.e. from a source system perspective).
1. The top-down approach
It starts by addressing a specific business problem or use case.
For example: developing a price optimization tool for your sales team by stitching together CRM data, transaction history, and external market data into a customized pipeline built solely to serve that one application.
- Pro: strong business alignment. Data products are directly tied to measurable outcomes.
- Con: risk of fragmentation. Solutions become use-case specific, difficult to reuse, and often turn into silos.
2. The bottom-up approach
It starts by building the technical foundation first.
For example: unlocking all data from your ERP and CRM systems by ingesting and modeling large volumes of operational data before concrete business use cases have been defined.
- Pro: strong reusability. Source-aligned data products improve consistency and quality.
- Con: slow time to value. It’s unclear which use cases will be enabled, delaying impact and eroding trust.
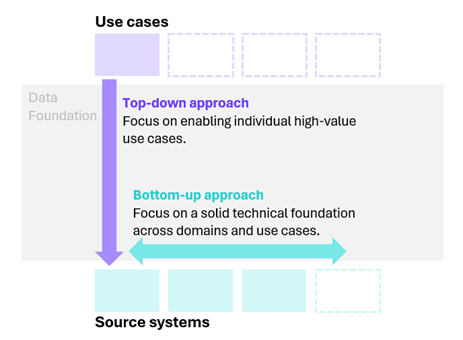
Figure 1. The top-down vs. bottom-up approach
3. The problem with either approach
Simply put, neither approach works well on its own:
- Lean too far top-down, and quick wins collapse because the underlying foundation cannot scale.
- Lean too far bottom-up, and you risk building a technically sound foundation that no one actively uses.
As a result, many organizations end up switching back and forth between these extremes, never fully unlocking the value of their data.
The solution: start top-down, but design for scale
To kickstart a data foundation effectively, we recommend a top-down, value-driven start combined with bottom-up design principles.
In practice, this means:
- Selecting priority use cases using a top-down approach, based on strategic importance and reuse potential.
- Applying scalable design principles when building data products, so today’s solution can evolve into tomorrow’s foundation.
This approach allows you to demonstrate value early while avoiding the common pitfall of creating one-off data solutions. The remaining risk is that a top-down start can still lead to fragmentation if design choices are made solely in service of the first use case.
The remainder of this article focuses on concrete design principles that mitigate these top-down pitfalls, as illustrated on the left-hand side of Figure 2. These principles ensure that value-driven data products can grow into a cohesive, reusable data foundation rather than a collection of isolated solutions.
Three design principles for scalable data products
As discussed in Data as a Product: Why Just Having Data Is Not Enough, data products are more than just data or pipelines. They encapsulate business logic, definitions, and assumptions. The way this logic is implemented determines whether a data product can evolve beyond its initial use case. The following design principles help ensure a top-down start remains sustainable.
1. Decouple data transformations to enable growth
Structure data products using clearly separated source → processing → sink layers so that ingestion, transformation, and delivery are explicitly isolated. This modular setup ensures that as new use cases emerge, individual parts of the data product can be extended, split, or reused—without rearchitecting the entire pipeline.
In practice, this means:
- Clearly separating source and sink logic, including all storage interactions and integrations with upstream or downstream data products.
- Isolating individual data transformation steps into distinct, composable blocks, each with a clear responsibility and output.
Why this matters:
- Enables faster creation and evolution of data products as scope expands.
- Keeps transformation logic readable, testable, and trustworthy for consuming teams.
2. Clearly document transformation logic and scope
Explicitly document the inputs, business rules, filters, and assumptions embedded in each data product so that its meaning and boundaries are unambiguous. This documentation should evolve together with the data product as scope and logic change.
In practice, this means:
- Listing all input sources and upstream data products the logic depends on.
- Describing applied business rules and filters, including rationale where relevant.
- Defining the intended scope and known exclusions to avoid misinterpretation by consumers.
Why this matters:
- Creates transparency around definitions and inclusions.
- Makes data products easier to extend, validate, and adapt as requirements evolve.
3. Design outputs for reuse across domains
Instead of optimizing outputs for a single business domain, deliberately design data product outputs to support multiple consuming domains from the start. This requires making consumption explicit and turning it into concrete design input.
In practice, this means:
- Identifying all potential consuming domains that are likely to use the data product now or in the near future.
- Capturing archetype consumption patterns and translating these patterns into detailed output requirements.
- Implementing these requirements in a consumer-aligned data model, defined through entities, attributes, and relationships that reflect shared business concepts rather than domain-specific needs.
Why this matters:
- Encourages reuse across the organization, accelerating new use case development.
- Reduces future rework by aligning outputs with real consumption needs upfront, making data products easier to extend and scale.
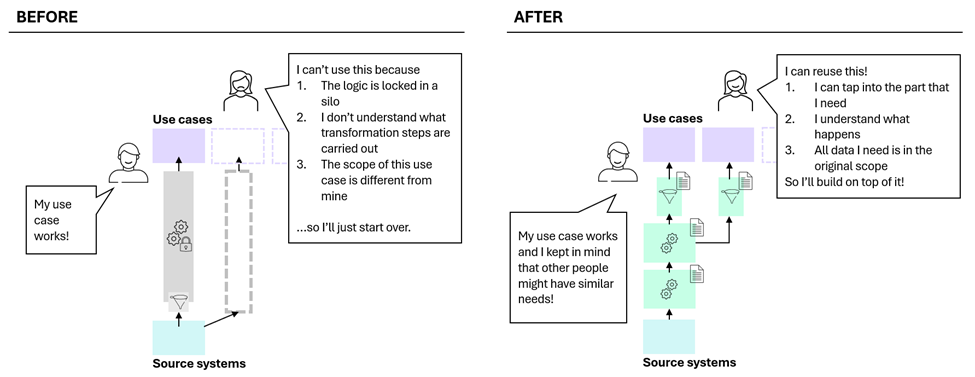
Figure 2. Before and after - the result of starting top-down while designing for scale.
Conclusion: building a data foundation that lasts
By starting with high-value use cases and applying scalable data product design principles, you can deliver immediate business impact without compromising the future. Done well, this approach results in a data foundation that grows organically from real business value rather than abstract architecture.
In short: don’t try to solve everything upfront—and don’t chase only quick wins either. The key to building a strong data foundation is delivering value today while deliberately designing for tomorrow.
This article was written by Bram van Koppen, Senior Data Engineer, and Phebe Langens, Data Scientist at Rewire.
Building your data capabilities, end-to-end
Our strategies elevate the performance of your data management from marginal or tactical results to transformational successes.
Explore our data management servicesHow semantic misalignment across teams and domains holds back data interoperability, and what it takes to build shared understanding at scale
In our article 2025 data management trends: the future of organizing for value, we identified interoperability as one of the three trends shaping how organizations create value with data in 2025.
But why is interoperability rising to the top of the agenda?
Primarily, data and AI use cases are moving from single-domain problems to cross-domain questions, driven by both offensive (e.g., data-driven strategies, cross-domain AI, data monetization) and defensive (e.g., CSRD and other external reporting requirements) data strategies. Take banking, for example: assessing customer lifetime value might require transaction data from finance, interaction logs from customer service, and risk profiles from compliance. Answering these high-impact, cross-domain questions requires more than just access to each domain’s systems – it demands bringing together data across departments, with consistent meaning and context. That’s where interoperability becomes essential.
We see two main challenges:
- A complex, diverse technology landscape makes it difficult to connect data
- Inconsistent semantics, or a lack of shared definitions, which make it difficult to interpret and use data across domains
While the first challenge is increasingly supported by modern approaches, the second – semantic alignment – remains highly organization-specific, and, in many cases, unresolved.
Recent trends, such as the shift toward domain-based data ownership, inspired by the introduction of the data mesh paradigm, have magnified the problem. Decentralization improves local data quality by giving teams accountability for the data they produce, but it also increases the risk of semantic misalignment between domains. ESG reporting is one example: it requires coordination across operations, HR, and finance, each using their own systems, language and metrics.
That is why modern data and AI use cases demand true data interoperability across the organization – not just technical connection, but a shared understanding. But how do you achieve that? To answer this, we first need to break interoperability down into its key components.
Breaking down data interoperability – and why semantic chaos is often overlooked
Before solving data interoperability, organizations need to recognize the different ways data alignment can break down across domains. Data, like language, is a structured representation of the real world – designed to convey meaning, but always shaped by context. And just as human communication can run into friction across languages or cultures, data integration can break down across systems or domains. These misalignments tend to fall into three categories.
- Technical interoperability: can systems connect at all? To communicate with someone abroad, your devices first need to connect; your phones must be online and your messaging apps must be compatible. In data, different technologies (like databases, APIs or platforms) must be able to establish a connection and exchange information, say, between a relational database and a data lake.
- Syntactic interoperability: can systems interpret the structure of the data? Once you’re connected, you need to use a structure both sides can follow. A French speaker and a Japanese speaker might switch to English to make the conversation possible. In data, this means aligning on formats, schemas (data structure definitions) and naming conventions. For example, one system might label a field client_id while another uses customer_number.
- Semantic interoperability: do systems agree on the meaning of the data? Even when speaking the same language, meaning can still diverge. Take the word football: it means different things in Europe and the US. The term is shared, but the concept isn’t. In data, the same happens when teams use terms like customer or revenue but define them differently depending on their context. Without a shared understanding, the data may appear integrated – but in practice, it creates confusion and leads to misinterpretation.
Of the three interoperability categories, semantic interoperability is the hardest to solve – and yet the most critical when working across domains. Unlike technical and syntactic issues, which are increasingly addressed with modern integration platforms and tooling, semantic alignment remains dependent on shared understanding. It requires agreement on what data actually means across systems, teams and business contexts – which is exactly what makes it so difficult to solve in practice.
There is no single owner of definitions; meaning is distributed across domains. Misalignment often remains invisible until something goes wrong. And it’s not just a technical issue – resolving semantics requires input from the business, coordinated processes, and a mature approach to governance. To illustrate, consider these two real-life examples:
- In our work with a global retail organization, two systems both used the term active customer. On the surface, the data appeared to represent the same concept, but one team had it defined as a customer who logged in recently, while another had it defined as someone who had made a purchase in the past quarter. When combining these data sources without understanding the differences, this results in misleading insights.
- In another client case – a digital automotive retailer – issues arose during financial forecasting when the finance team relied on the commerce team’s definition of stock. While the commercial team defined stock as cars currently available for sale, the finance team was looking for all vehicles on the balance sheet. As a result, the financial projection was made using a fraction of the actual inventory – a semantic mismatch with material consequences.
So, even when organizations succeed in technically connecting their data – through modern platforms or federated query engines like Trino – semantic chaos often persists below the surface. In the worst case, it goes unnoticed, leading to flawed insights and strategic errors. In the best case, it’s recognized but resolving it requires extensive coordination across teams, delaying decisions and slowing down AI development.
That’s why solving semantic interoperability is so essential – and so often overlooked.
Solving semantic interoperability is a strategic investment
Once semantic interoperability is recognized as a critical challenge, the key question becomes: How do you align meaning across the organization?
In practice, we see two common approaches for organizations to manage meaning across teams and domains:
- The first is built on SLA-based standards (which define what data are delivered, how they are structured and how they should be used), where data-producing teams define agreements about how their data is produced, documented and intended to be consumed.
- The second is ontology-based modeling, which introduces a shared, formal (graph-based) model to represent the core business concepts and how they relate, creating a common language for data. Given the goal of cross-domain value creation, only concepts that are reused or interpreted across domains need to be modeled, allowing teams to participate flexibly where needed.
While ontologies require more upfront effort and governance, they provide a strong foundation for reusability, AI enablement and enterprise-wide consistency. For example, they can be used to create structured business context for GenAI agents, which helps address one of the most common fears in enterprise AI adoption: agents making decisions without the right context. A well-designed ontology enables AI systems to reason over business terms, relationships, and constraints – making outputs more aligned, explainable, and trustworthy. (See our blog post on RAG and knowledge graphs for a deeper dive into how ontologies support AI context and semantic reasoning.) Ontologies also open the door to fine-grained access management. By specifying policies on the shared semantic model – rather than hard-coded on files or specific data – organizations can define access controls based on business concepts, roles, or relationships, making it easier to adapt to changing compliance needs or organizational structures.
Solving semantic interoperability, whether through standards or ontologies, starts with understanding that this is not just a technical task. It’s a strategic investment:
- Establishing standards or ontologies takes time and expertise.
- Governance must be driven by value in data consumption, not just technical consistency.
- Leadership must make deliberate choices about which definitions matter, where alignment is needed, and how that alignment will be enforced across the organization.
The takeaway: solve your semantics to enable interoperability at scale
Ultimately, addressing semantic interoperability is a critical step in solving the broader interoperability challenge. Technical connectivity and structural alignment are foundational, but without shared meaning, data remains fragmented, misunderstood, or misused. As data and AI use cases increasingly span teams, systems, and domains, organizations that succeed will be those that treat interoperability, especially semantic alignment, as a capability to actively build, govern, and scale.
What’s next?
In our next post, we will take a closer look at ontology-based modeling in practice, including a real-world example and practical tips for getting started. For now, ask yourself the question: How does your organization define and manage the language your data speaks?
This article was written by Marnix Fetter, data scientist, and Eva Scherders, data & AI engineer at Rewire.
Building your data capabilities, end-to-end
Our strategies elevate the performance of your data management from marginal or tactical results to transformational successes.
Explore our data management services