Blog
Demystifying the enablers and principles of scalable data management.

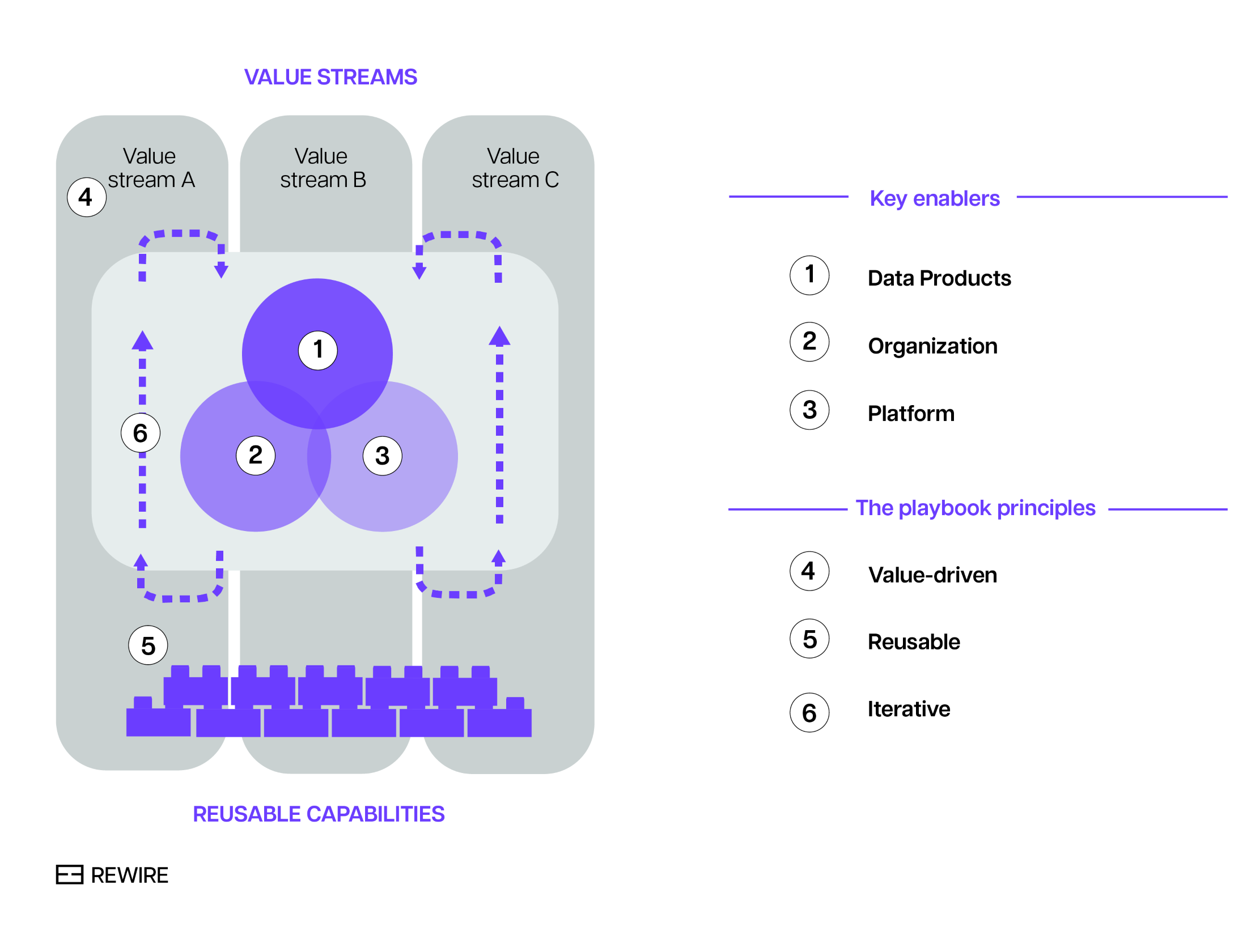
In the first instalment of our series of articles on scalable data management, we saw that companies that master the art of data management consider three enablers: (1) data products, (2) organizations, and (3) platforms. In addition, throughout the entire data management transformation, they follow three principles: value-driven, reusable, and iterative. The process is shown in the chart below.
Exhibit 1. The playbook for successful scalable data management.
Now let’s dive deeper into the enablers and principles of scalable data management.
Enabler #1: data products
Best practice dictates that data should be treated not just as an output, but as a strategic asset for value creation with a comprehensive suite of components: metadata, contract, quality specs, and so on. This means approaching data as a product, and focusing on quality and the needs of customers.
There are many things to consider, but the most important questions concern the characteristics of the data sources and consumption patterns. Specifically:
- What is the structure of the data? Is there a high degree of commonality in data types, formats, schemas, velocities? How could these commonalities be exploited to create scalability?
- How is the data consumed? Is there a pattern? Is it possible to standardize the format of output ports?
- How do data structure and data consumption considerations translate into reusable code components to create and use data products faster over time?
Enabler #2: organization
This mainly concerns the structure of data domains and clarifying the scope of their ownership (more below). This translates into organizational choices such as whether data experts are deployed centrally or decentrally. Determining factors include data and AI ambitions, use case complexity, data management maturity, and the ability to attract, develop, and retain data talent. To that end, leading companies consider the following:
- What is the right granularity and topology of the data domains?
- What is the scope of ownership in these domains? Does the ownership merely cover definitions, and does it (still) rely on a central team for implementation or have domains real end-to-end ownership over data products?
- Given choices on these points, what does it mean for how to distribute data experts (e.g. data engineers, data platform engineers)? Is that realistic given the size or ability to attract and develop talent or should choices be reconsidered?
Enabler #3: platforms
This enabler covers technology platforms - specifically the required (data) infrastructure and services that support the creation and distribution of data products within and between domains. Organizations need to consider:
- How best to select services and building blocks to construct a platform? Should one opt for off-the-shelf solutions, proprietary (cloud-based) services, or open-source building blocks?
- How much focus on self-service is required? For instance, a high degree of decentralization typically means a greater focus on self-service within the platform and the ability of building blocks to work in a federated ways.
- What are the main privacy and security concerns and what does that mean for how security-by-design principles are incorporated into the platform?
Bringing things together: the principles of scalable data management
Although all three enablers are important on their own, the full value of AI can only be unlocked by leaders who prudently balance them throughout the whole data management transformation. For example, too much focus on platform development typically leads to organizations that struggle to create value as data (or rather, its value to the business) has been overlooked. On the other hand, too data-centric companies often struggle with scaling as they haven’t arranged the required governance, people, skills and platforms to remain in control of large scale data organizations.
In short, how the key enablers are combined is as important as the enablers on their own. Hence the importance of developing a playbook that spells out how to bring things together. It begins with value, and balances the demands on data, organization and platform to create reusable capabilities that drive scalability in iterative, incremental steps. This emphasis on (1) value, (2) reusability and (3) iterative approach lies at the heart of what companies who lead in the field of scalable data management do.
Let’s review each of these principles.
Principle #1: value, from the start
The aim is to avoid two common pitfalls: the first is starting a data management transformation without a clear perspective on value. The second is failing to demonstrate value early in the transformation. (Data management transformation projects can last for years, and failing to demonstrate value early in the process erodes the momentum and political capital.) Instead of focusing on many small initiatives, it is essential to prioritize the most valuable use cases. The crucial – and arguably the hard bit – is to consider not only the impact and feasibility of individual use cases but also the synergies between them.
Principle #2: reusable capabilities
Here the emphasis is on collecting, formalizing and standardizing the capabilities from core use cases. Then, re-use them for other use cases, thereby achieving scalability. Reusable capabilities encompass people capabilities, methodologies, standards and blueprints. Think about data product blueprints that include standards for data contracts, minimum requirements on meta data and data quality, standards on outputs and inputs, as well as methods on how to organize ownership, development, and deployment.
Principle #3: building iteratively
Successful data transformation progress iteratively towards their ultimate objectives, with each step being the optimal iteration in light of future iterations. Usually this requires (1) assessing the data needs of the highest-value use cases and developing data products that address these needs. Then, (2) considering where it impacts the organization and taking steps towards the new operating model. The key here is to identify the most essential platform components. Since they typically have long lead times, it's important to mitigate gaps through pragmatic solutions - for example ensuring that technical teams assist non-technical end users, or temporarily implementing manual processes.

Making scalable data management a reality
Market leaders reinvent and reorganize themselves around data. We can help you with this.
Explore our data management servicesUnlocking the full value of data
Data transformations are notoriously costly and time consuming. But it doesn't have to be that way: the decoupled, decentralized nature of modern technologies and data management practices allow for a gradual, iterative, but also targeted approach to change. When done right, this approach to data transformation provides enormous opportunities for organizations to leapfrog their competitors and create the data foundation for boundless ROI.
This article was written by Freek Gulden, Lead Data Engineer, Tamara Kloek, Principal, Data & AI Transformation, and Wouter Huygen, Partner & CEO.




