Blog
In this first of a series of articles, we discuss the gap between the theory and practice of scalable data management.

Fifteen trillion dollars. That’s the impact of AI by 2030 on global GDP according to PwC. Yet MIT research shows that, while over 90% of large organizations have adopted AI, only 1 in 10 report significant value creation. Granted, these numbers are probably to be taken with a grain of salt. But even if these numbers are only directionally correct, it’s clear that while the potential from AI is enormous, unlocking it is a challenge.
Enters data management.
Data management is the foundation for successful AI deployment. It ensures that the data driving AI models is as effective, reliable, and secure as possible. It is also a rapidly evolving field: traditional approaches, based on centralized teams and monolithic architectures, no longer suffice in a world of exploding data. In response to that, innovative ideas have emerged, such as data mesh, data fabric, and so on. They promise scalable data production and consumption, and the elimination of bottlenecks in the data value chain. The fundamental idea is to distribute resources across the organization and enable people to create their own solutions. Wrap this with an enterprise data distribution mechanism, and voilà: scalable data management! Power to the people!
A fully federated model is not the end goal. The end goal is scalability, and the degree of decentralization is secondary.
Tamara Kloek, Principal at Rewire, Data & AI Transformation Practice Area.
There is one problem however. The theoretical concepts are well known, but they fall short in practice. That’s because there are too many degrees of freedom when implementing them. Moreover, a fully federated model is not always the end goal. The end goal is scalability, and the degree of decentralization is secondary. So to capitalize on the scalability promise, one must navigate these degrees of freedom carefully, which is far from trivial. Ideally, there would be a playbook with unambiguous guidelines to determine the optimal answers, and explanations on how to apply them in practice.
So how do we get there? Before answering this question, let’s take a step back and review the context.
Data management: then and now
In the 2000s, when many organizations undertook their digital transformation, data was used and stored in transactional systems. For rudimentary analytical purposes, such as basic business intelligence, operational data was extracted into centralized data warehouses by a centralized team of what we now call data engineers.
This setup no longer works. What has changed? Demand, supply and data complexity. All three have surged, largely driven by the ongoing expansion of connected devices. Estimates vary by source, but by 2025 the number of connected (IoT) devices is projected to be between 30 to 50bn globally. This trend creates new opportunities and reduces the gap between operational and analytical data: analytics and AI are being integrated into operational systems, using operational data to train prediction models. And vice versa: AI models generate predictions to steer and optimize operational processes. The boundary between analytical and operational data becomes blurred, and requires a reset on how and where data is managed. Lastly, privacy and security standards are ever increasing, not least driven by new a geopolitical context and business models that require data sharing.
Organizations that have been slow to adapt to these trends are feeling the pain. Typically they experience:
- Slow use-case development, missing data, data being trapped in systems that are impossible to navigate, or bottlenecks due to centralized data access;
- Difficulties in scaling proofs-of-concepts because of legacy systems or poorly defined business processes;
- Lack of interoperability due to siloed data and technology stacks;
- Vulnerable data pipelines, with long resolution times if they break, as endless point-to-point connections were created in an attempt to bypass the central bottlenecks;
- Rising costs as they patch their existing system by adding people or technology solutions, instead of undertaking a fundamental redesign;
- Security and privacy issues, because they lack end-to-end observability and security-by-design principles.
The list of problems is endless.
New paradigms but few practical answers
About five years ago, new data management paradigms emerged to provide solutions. They are based on the notion of decentralized (or federated) data handling, and aim to facilitate scalability by eliminating the bottlenecks that occur in centralized approaches. The main idea is to introduce decentralized data domains. Each domain takes ownership of its data by publishing data products, with emphasis on quality and ease of use. This makes data accessible, usable, and trustworthy for the whole organization.
Domains need to own their data. Self-serve data platforms allow domains to easily create and share their data products in a uniform manner. Access to essential data infrastructure is democratized, and, as data integration across different domains is a common requirement, a federated governance model is defined. This model aims to ensure interoperability of data published by different domains.
In sum, the concepts and theories are there. However, how you make them work in practice is neither clear, nor straightforward. Many organizations have jumped on the bandwagon of decentralization, yet they keep running into challenges. That’s because the guiding principles on data, domain ownership, platform and governance provide too many degrees of freedom. And implementing them is confusing at best, even for the most battle-hardened data engineers.
That is, until now.
Delivering on the scalable data management promise: three enablers and a playbook
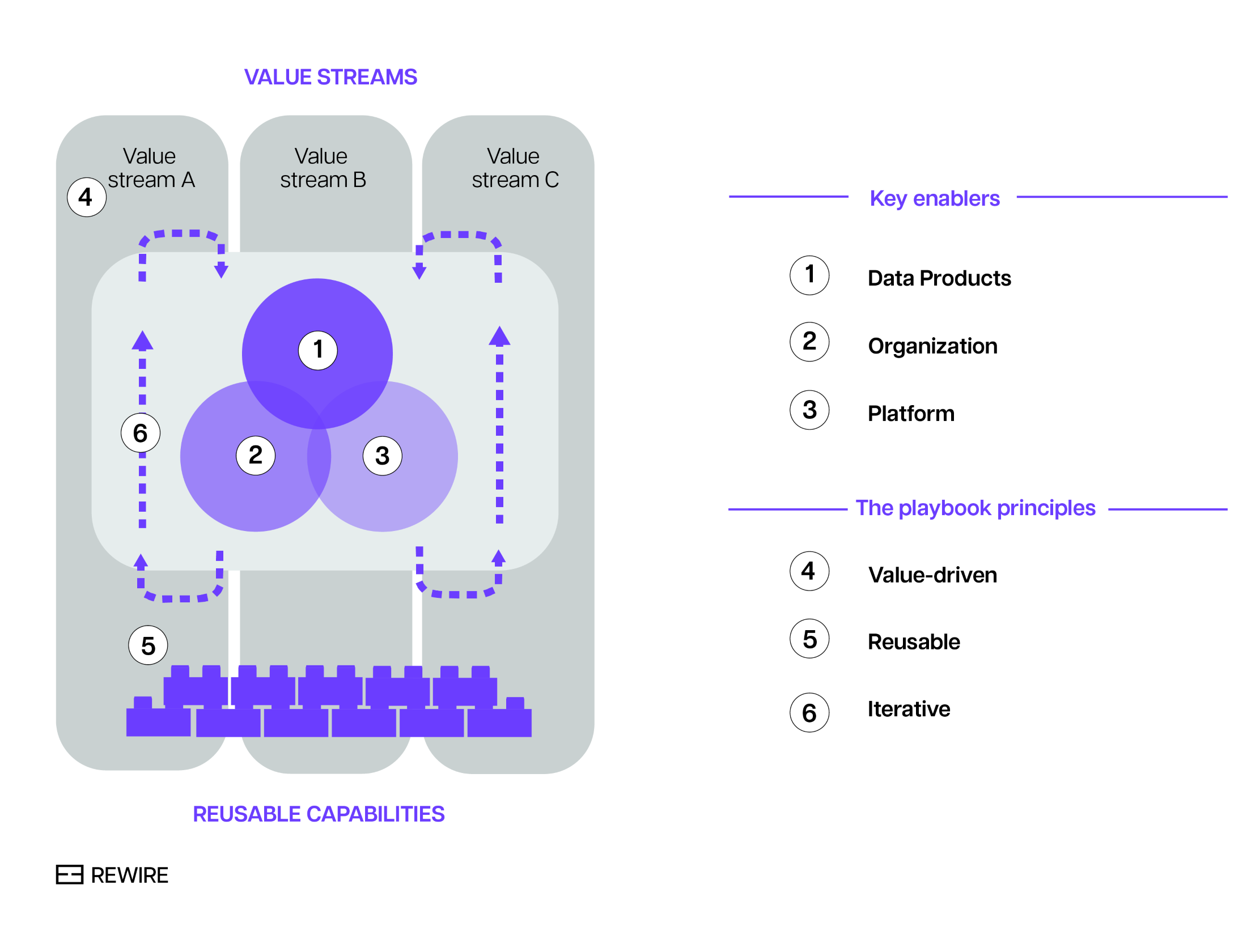
Years of implementing data models at clients have taught us that the key to success lies in doing two things in parallel that touch on the “what” and “how” of scalable data management. The first step is to translate the high-level principles of scalable data management into organization-specific design choices. This process is structured around three enablers - the what of scalable data management:
- Data, where data is viewed as a product.
- Organization, which covers the definition of data domains and organizational structure.
- Platforms, which by design should be scalable, secure, and decoupled.
The second step addresses the how of scalable data management: a company-specific playbook that spells out how to bring things together. This playbook is characterized by the following principles:
- Value-driven: goal is to create value from the start, with data being the underlying enabler.
- Reusable: capabilities are designed and developed in a way that they are reusable across value streams.
- Iterative: the process of value creation balances the demands on data, organization and platform with reusable capabilities that drive scalability in iterative, incremental steps.
The interplay between the three enablers (data, organizations, platforms) and playbook principles (value-driven, reusable, and iterative) are summarised in the chart below.

Making scalable data management a reality
Market leaders reinvent and reorganize themselves around data. We can help you with this.
Explore our data management servicesExhibit 1. The playbook for successful scalable data management.
Delivering on the promise of scalability provides enormous opportunities for organizations to leapfrog the competition. The playbook to scalable data management - designed to achieve just that - has emerged through collaborations with clients across a range of industries, from semiconductors to finance and consumer goods. In future blog posts, we discuss the finer details of its implementation and the art of building scalable data management.
This article was written by Freek Gulden, Lead Data Engineer, Tamara Kloek, Principal, Data & AI Transformation, and Wouter Huygen, Partner & CEO.




