Blog
What Generative AI can and cannot do. And what it means for the future of business.

Meet Edmond de Belamy, the portrait painting displayed above. On Thursday October 25th in 2018, Edmond was auctioned off by Christie’s for a whopping $432,500. The signature on the bottom right of Edmond shows its artist to be
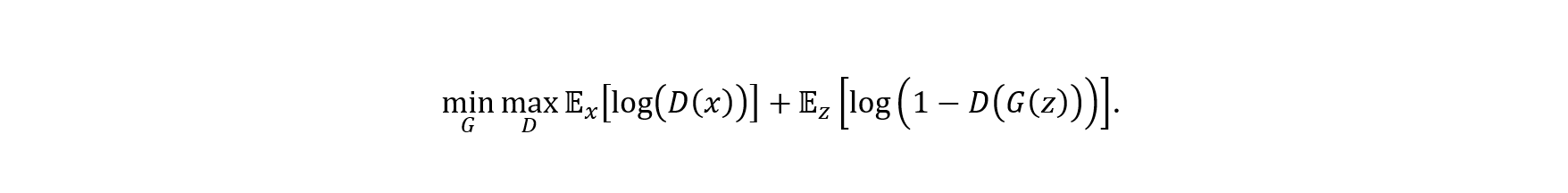
This impressive-looking formula represents a GAN network: a generative AI-model avant-la-lettre. Edmond de Belamy became the first AI-generated artwork to be auctioned off by a major auction house.
The Belamy portrait was the first time we were truly impressed by the capabilities of a GenAI model. Nowadays, its quality is nothing special. In fact, we have rapidly gotten used to image generation models producing photorealistic images, text generation models that generate e-mail texts and meeting summaries better than we could ourselves, and even LLMs that support us developers and data scientists in writing code.

The breakthrough of GenAI, heralded by the release of ChatGPT in December 2022, has truly been amazing. It may almost lead you to believe that the age of humans is over, and the age of machines has now truly begun.
That is, until you start asking these GenAI models the hard questions. Such as:
Can you give me an odd number that does not have the letter “E” in it?

Anyone who can read could tell you GPT-4 botched that question. The correct answer would have been: no, I cannot, because such a number does not exist. Despite its ‘reasoning’, ChatGPT manages to confidently announce the number “two” has an “e” in it (note: it doesn’t), and continues to produce “two hundred one” as an example of an odd number that does not have an “e” in it (note: it does).
Another favorite pastime of ours is to ask LLM models to play chess with us. Our typical experience: they will claim they know the rules, and proceed to happily play illegal moves halfway through the game, or conjure up ghost pieces that manage to capture your knight out of nowhere.
The internet is full of entertaining examples of ChatGPT getting tasks wrong that humans solve without a second thought. These issues are not ChatGPT-specific either. Other LLM-providers, such as Anthropic, Google, Meta, and so on, face similar challenges.
So, on the one hand, GenAI models have proven to be an impressive breakthrough. On the other hand, it is clear that they are far from infallible. This begs the question:
What is the breakthrough of GenAI really?
And more importantly:
What does this mean for someone wanting to make the most of this technology?
Dissecting the GenAI breakthrough
In the 21st century we have seen the breakthrough of machine learning ending the ‘AI winter’ of the 1990s. Machine learning is essentially computers generalizing patterns in data. Three things are needed to do that well: algorithms for identifying patterns, large amounts of data to identify the patterns in, and computation power to run the algorithms.
By the start of the 2000s, we did know a fair bit about algorithms. The first Artificial Neural Networks, which form the foundation of ‘deep learning’, were published in 1943 (McCulloch et al., 1943). Random forest algorithms, the precursors to modern tree ensemble algorithms, were initially designed in 1995 (Breiman et al., 2001).
The rise of the digital age added the other two ingredients. We saw exponential growth in the amount of stored data worldwide. Simultaneously computing power kept getting exponentially cheaper and more easily accessible. All of a sudden, ‘machine learning’ and therefore AI, started to fly. Apparently, tossing large amounts of data, and huge amounts of computing power at a suitable algorithm can achieve a lot.
With machine learning we managed to have a go at quite a few problems that were previously considered difficult: image recognition, speech-to-text, playing chess. Some problems remained remarkably difficult, however. One of which was automated understanding and generation of human language.
This is where LLMs come in. In 2018, the same year our good fellow Edmond was created, OpenAI published a remarkable paper. They introduced a class of algorithms for language understanding called Generative Pre-trained Transformers, for short: “GPT” (Radford et al., 2018). This combined two key ideas. One that allowed them to “pre-train” language models on low-quality text as well as beautifully crafted pieces. And another that allowed these algorithms to benefit efficiently from large amounts of computing power. Essentially, they asked these models to learn how to predict the next word in a sentence, ideally enabling them to generate their own sentence if they became good enough at that.
GPT-1 was born with this paper in 2018, but OpenAI did not stop there. With their new algorithms they were able to scale GPT-1 both in model size, but just as importantly in terms of how much data it could be fed. GPT-3, the model that powered ChatGPT at its launch in 2022, was reportedly trained on almost 500 billion text tokens (which is impressive, but not even close to the ‘entire internet’, as some enthusiasts claim), and with millions of dollars of computing power.
Despite its insane jump in performance, the fundamental task of GPT-3 remains the same as it was for GPT-1. It is a very large, very complex machine learning language model trained to predict the next word in a sentence (or predict the next ‘token’, to be more precise). What is truly remarkable, however, is the competencies that emerge from this skill, which impressed even the most sceptical.
Emergent competencies of Large Language Models
Predicting the next word is cool, but why are these LLMs heralded by some as the future of everything (and by some as the start of the end of humanity)?
Despite being trained as “next-word-predictors” LLMs have begun to show competencies that truly do make them game changers. To be able to predict the next word based on a prompt, they have to do three things:
- Understand: making sense of unstructured data from humans and systems;
- Synthesize: processing information to ‘connect the dots’ and formulate a single, sensible response;
- Respond: generating responses in human or machine-readable language that provide information or initiate next steps.

Let’s unpack all this by looking at an example.

In this example, we asked ChatGPT powered by GPT-4 to solve a problem that may seem easy to anyone with basic arithmetic knowledge. Let’s pause to appreciate why ChatGPT’s ability to solve the problem is remarkable regardless.
Firstly, ChatGPT understands what we are asking. It manages to grasp that this question requires logical reasoning and gives us an answer that includes argumentation and a calculation. Furthermore, it can synthesize a correct response to our request, generating essentially ‘new’ information that was not present in the original prompt: the fact that we will have 3 loaves of bread left at the end of the day. Finally, it can respond with an answer that makes sense. In this case, it’s a human language response, wrapped in some nice formatting, but ChatGPT can also be used to generate ‘computer language’ in the form of programming code.
To put this into perspective: previous systems that were able to complete such prompts, would have generally been composed of many different components working together, tailored to this particular kind of problem. We’d have a text understanding algorithm, that extracts the calculation to be done from the input prompt. Then a simple calculator to perform the calculation, and a ‘connecting’ algorithm that feeds the output from the first algorithm into the calculator. Finally, we’d have a text generating system that takes the output and inputs the text into a pre-defined text template. With ChatGPT – we can have one model perform this whole sequence, all by itself. Lovely.
To put it in even more perspective: these types of problems were still difficult for older versions of ChatGPT. It shows that these emerging competencies are still improving in newer versions of state-of-the-art models.

So far, we haven’t even considered models that can do understanding, synthesis and generation across multiple types of input and outputs (text, images, sound, video, etc.) These multi-modal models are all the rage since early 2024. The world of GenAI is truly moving quickly.
So what does it mean for businesses?
The talents of GenAI are truly impressive, making them a very versatile tool that opens up endless possibilities. It can craft beautiful e-mails, help generate original logos, or speed up software development.
Even more promising is GenAI’s ability to make sense of unstructured data at scale. Estimates put the amount of unstructured data to be about 80-90% of all the data that companies possess. Extracting value from this data through traditional means is time-consuming and challenging at best. This has led to unstructured data being largely ignored for many commercial use cases. Yet GenAI can plough through it and generate outputs tailored to the desired use cases. You can uncover the needles in haystacks to fuel human decisions, or enable more traditional AI systems to learn from this data. Imagine how powerful these systems would become if you increased the amount of useful information available to them by a factor 5 to 10.
Now, if you’ve been following some of the AI news lately, you’ll know we can take it even one step further and think about ‘Agentic AI’, that is, agents powered by AI. These systems that cannot only think, but actually do. In future, they will likely enable large scale automation at first, and later complete organizational transformations.
Research into how to make this work is in full swing as of the summer of 2024. The extent to which autonomous AI agents are already feasible is a hotly debated topic. At any rate, ‘simple’ agents, are now being developed that are beginning to capitalize on the AI promise. Making the most of these will require their users to carefully consider how to manage their performance, and balance two opposing characteristics: hallucinations (i.e. nonsensical results, which some argue are an inescapable feature of LLMs), and their effectiveness.
Against this backdrop, it won’t be long before the early adopters get a head start on the laggers. Teams and organizations that take the time to identify opportunities and capitalize on them are set to move far ahead of the competition.
This article was written by Simon Koolstra, Principal and Renske Zijm, Data scientist at Rewire.

Turning Generative AI potential into bottom line impact
Our strategies enable you to harness generative AI, moving beyond marginal or tactical gains to achieve transformational success.
Explore our Generative AI services



