Blog
Fine-tuning can worsen factual correctness in specialized application domains. We discuss the implications.

This article originally published on LinkedIn. The writer, Wouter Huygen is partner and CEO at Rewire.
A new paper reveals that fine-tuning is not a wonder drug for prevailing LLM hallucinations. Rather the reverse: fine-tuning can actually worsen performance when aiming to develop factual correctness in specialized application domains.
Using supervised learning on new knowledge fine-tunes hallucinations, instead of enhancing accuracy
These findings could have profound implications. What if these areas precisely provide most of the value from LLM use cases?
The hard problem of hallucinations
The beauty of LLMs is that they are very generic and general-purpose: they contain “knowledge” on a very wide range of subjects covered in the training data. This forms the basis for the claim that the current path will get us (close) to AGI. I don’t think that is true, but that’s for another day.
Clearly, generative AI currently works only up to a point. Measuring hallucination rates is notoriously difficult, but roughly speaking the tech works well in 80% of the cases. And yes, performance depends on many factors including the prompting abilities of the user. That being said, getting rid of the remaining 20% is arguably the biggest headache of the AI industry.
A long standing question in neuroscience and philosophy is how consciousness arises in the brain. How does a bunch of molecules and electromagnetic waves produce the miracle of our conscious experience? This is referred to as the hard problem of consciousness. But what if science has the premise all wrong? What if consciousness does not arise from matter, but matter is (an illusion) formed in consciousness?
Hallucinations are the current hard problem-to-crack for AI
Similarly, hallucinations are a cause of generative AI technology, not a consequence. The technology is designed to dream up content, based on probabilistic relationships captured in the model parameters.
Big tech proclaims that the issue can be solved through further scaling, but experts in the field increasingly recognize we have to view it as a remaining feature, not a bug. After all, who would not be hallucinating after reading the entire internet ;-)
For the short term, the applicability of LLMs – despite their amazing feats – remains more limited than we might hope. Especially in high stakes situations and/or very specialized areas. And these might just be the areas that herald the most value (e.g. in healthcare, proving accurate diagnostic/treatment solutions).
Unless fundamental algorithmic breakthroughs come along, or scaling proves to work after all, we have to learn how to make the best of what we've got. Work with the strengths, while minimizing downside impact.
Using Fine-Tuning to develop domain specific applications
Since the beginning of the Gen AI hype, fine-tuning is touted as one of the ways to improve performance on specific application areas. The approach is to use supervised learning on domain-specific data (e.g. proprietary company data) to fine-tune a foundational (open source) model to specialize it for a certain use case and increase factuality.
Intuitively this makes sense. The foundation model is pre-trained on generic text prediction with a very broad base of foundational knowledge. Further fine-tuning would then provide the required specialization, based on proprietary and company-specific facts.
Fine-tuning does not work well for new information
A recent paper investigates the impact of fine-tuning on new information. The authors aimed to validate the hypothesis that new knowledge can have unexpected negative impact on model performance, rather than improving it in a specific area. The outcomes are surprising, counter-intuitive at first glance, and impactful.
Fine-tuning with new knowledge works much slower than for existing knowledge (i.e. knowledge that was included in the pre-training data set). But most importantly, beyond a certain point of training, new knowledge deteriorates model performance on existing knowledge. In other words, incorporating specific new information in fine-tuning increases hallucinations. Worse yet, the hallucination rate grows linearly with more training in unknown content.
In intuitive terms, it seems as if the model gets confused with new information and “unlearns” existing knowledge.
Exhibit 1. Train and development accuracies as a function of the fine-tuning duration, when fine-tuning on 50% Known and 50% Unknown examples.
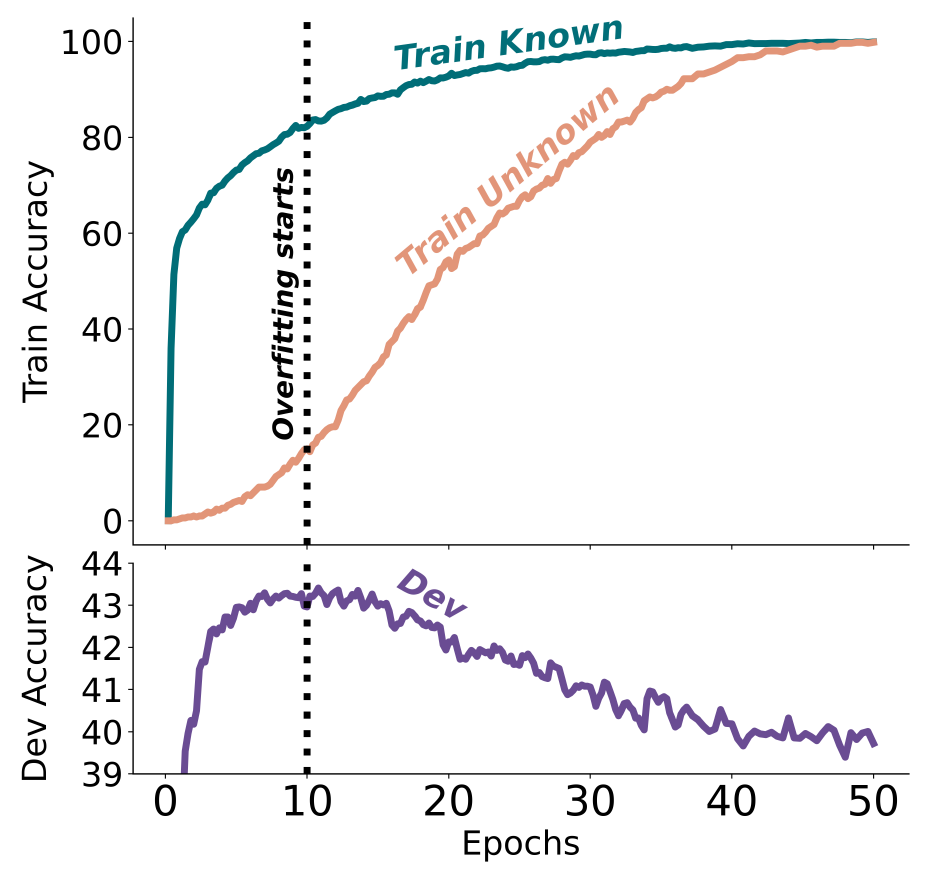
Source: paper from Zorik Gekhman et al.
These conclusions have serious implications for anyone aiming to develop specialized LLM use cases. Fine-tuning remains useful for strengthening model performance in known areas as well as improving the form and structure of the desired output. But using fine-tuning to increase factuality on new information does not work well and has undesirable, opposite affects.
The unfortunate correlation between accuracy and value
Using LLMs to build knowledge assistants is a promising use case across many fields. These use cases thrive well in highly knowledge-intensive industries, allowing users to query situation specific information on-demand. This includes healthcare workers, pharmaceutical advisors, customer service, professional services, etc. Not only do these assistants increase effectiveness and efficiency of their users, they also allow to accumulate enterprise knowledge and IP in a much more sustainable and scalable manner. They become like digital co-workers that never resign, unless you fire them.
As long as humans can be in the loop, verifying output, or when the impact of inaccurate information is low, the current LLM technology is already good enough. But in many situations, most of the value would actually come from reliability and factual correctness rather than an 80%- answer that can be manually adjusted (like drafting an email).
What to do instead?
To enhance performance in specific application areas amidst existing technological constraints, companies and developers must adopt a pragmatic and empirical engineering approach. This involves employing a combination of sophisticated techniques to forge optimal solutions. Innovations like Retrieval-Augmented Generation (RAG), fine-tuning processes accounting for new versus existing knowledge, advanced context embedding, and post-processing output verification are reshaping our methodologies daily.
The new insights discussed here demonstrate the importance to stay abreast of the fast developing field to continue pushing the performance boundaries of Gen AI applications. Until new breakthroughs happen in foundation models, we have to keep learning new tricks of the trade to get the most out of today's state of the art.




