A handful of principles will set you up for success when bringing GenAI to enterprise data.
As highlighted in our 2025 Data Management Trends report, the rapid evolution of LLMs is accelerating the shift of GenAI models and agentic systems from experimental pilots to mission-critical applications. Building a proof of concept that taps a single data source or uses a few prompts is relatively simple. But delivering real business value requires these models to access consistent, high-quality data—something often trapped in silos, buried in legacy systems, or updated at irregular intervals.
To scale from pilot to production, organizations need a more structured approach—one grounded in solid data management practices. That means integrating with enterprise data, enforcing strong governance, and ensuring continuous maintenance. Without this foundation, organizations risk stalling after just one or two operationalized GenAI use cases, unable to scale or accommodate new GenAI initiatives, due to persistent data bottlenecks. The good news is that those early GenAI implementation efforts are the ideal moment to confront your data challenges head-on and embed sustainable practices from the start.
How, then, can data management principles help you build GenAI solutions that scale with confidence?
In the sections that follow, we’ll look at the nature of GenAI data and the likely challenges it poses in your first value cases. We’ll then explore how the right data management practices can help you address these challenges—ensuring your GenAI efforts are both scalable and future-proof.
Understanding the nature of GenAI data
GenAI data introduces a new layer of complexity that sets it apart from traditional data pipelines, where raw data typically flows into analytics or reporting systems. Rather than dealing solely with structured, tabular records in a centralized data warehouse, GenAI applications must handle large volumes of both structured and unstructured content—think documents, transcripts, and other text-based assets—often spread across disparate systems.
To enable accurate retrieval and provide context to the model, unstructured data first be made searchable. This typically involves chunking the content and converting it into vector embeddings or exposing it via a Model Context Protocol (MCP) server, depending on the storage provider (more on that later). Additional context is increasingly delivered through metadata, knowledge graphs, and prompt engineering, all of which are becoming essential assets in GenAI architectures. Moreover, GenAI output often extends beyond plain text. Models may generate structured results—such as function calls, tool triggers, or formatted prompts—that require their own governance and tracking. Even subtle variations in how text is chunked or labeled can significantly influence model performance.
Because GenAI taps into a whole new class of data assets, organizations must treat it differently from standard BI or operational datasets. This introduces new data management requirements to ensure that models can reliably retrieve, generate, and act on timely information—without drifting out of sync with rapidly changing data. By addressing these nuances from the outset, organizations can avoid performance degradation, build trust, and ensure their GenAI solutions scale effectively while staying aligned with business goals.
Start smart: consider data representability
Selecting your first GenAI value case to operationalize is a critical step—one that sets the tone for everything that follows. While quick experiments are useful for validating a model’s capabilities, the real challenge lies in integrating that model into your enterprise architecture in a way that delivers sustained, scalable value.
Choosing the right value case requires more than just identifying an attractive opportunity. It involves a clear-eyed assessment of expected impact, feasibility, and data readiness. One often overlooked but highly valuable criterion is data representability: how well does the use case surface the kinds of data challenges and complexities you’re likely to encounter in future GenAI initiatives?
Your first operationalized value case is, in effect, a strategic lens into your data landscape. It should help you identify bottlenecks, highlight areas for improvement, and stress-test the foundations needed to support long-term success. Avoid the temptation to tackle an overly ambitious or complex use case out of the gate—that can easily derail early momentum. Instead, aim for a focused, representative scenario that delivers clear early wins while also informing the path to sustainable, scalable GenAI adoption.
Don’t get stuck: Answer these critical data questions
The targeted approach described above delivers the early tangible win needed to get stakeholder buy-in—and, more critically, it exposes underlying data issues that might otherwise go unnoticed. Here are typical data requirements for your first GenAI use case, along with the key challenge they create and core questions you’ll need to answer.
| Requirement | Challenge | Key questions |
| Integrated information | Previously untapped information (for example, pdf documents), is now a key data source and must be integrated with your systems. | * Where is all this data physically stored? Who maintains ownership of each source? * Do you have the necessary permissions to access them? * Does the data storage tool provide a MCP server to interact with the data? |
| Searchable knowledge system | Searchable documents must be chunked, embedded, and updated in a vector database—or exposed via an MCP server—creating new data pipeline and infrastructure demands. | * Can you find a reliable embedding model for capturing the nuances in your business? * How frequently must you re-embed to handle updates? * Are the associated costs manageable at scale? |
| Context on how data is interconnected | Reasoning capabilities require explicitly defined relationships—typically managed through a knowledge graph. | * Is your data described well enough to construct such a graph? * Who will ensure these relationships and definitions stay accurate over time? |
| Retrieval from relational databases by an LLM | Models need rich, well-documented metadata to understand and accurately query relational data. | * Are vital metadata fields consistent and detailed? * Do you have the schemas and documentation required for the model to navigate these databases effectively? |
| Defining prompts, output structures and tool interface | Prompts, interfaces, and outputs must be reusable, versioned, and traceable to scale reliably and maintain trust. | * How do you ensure these prompts and interfaces are reusable? * Can you track changes for auditability? * How do you log their usage to troubleshoot issues? |
| Evaluate model outputs over time | User feedback loops are essential to monitor performance, but collecting, storing, and acting on feedback systematically is lacking. | * How do you store feedback? * How do you detect dips in accuracy or relevance? * Can you trace poor results back to specific data gaps? |
| Access to multiple data sources for the LLM | GenAI creates data leakage risks (e.g. prompt injection), requiring access controls to secure model interactions. | * Which guardrails or role-based controls prevent unauthorized data exposure? * How do you ensure malicious prompts don’t compromise the agent? |
Look beyond your first pilot: apply data product thinking -from day one
A common mistake is solving data challenges only within the narrow context of the initial pilot—resulting in quick fixes that don’t scale. As you tackle more GenAI projects, inconsistencies in data structures, metadata, or security can quickly undermine progress. Instead, adopt a reusable data strategy from day one—one that aligns with your broader data management framework.
Treat core assets like vector databases, knowledge graphs, relational metadata, and prompt libraries as data products. That means assigning ownership, defining quality standards, providing documentation, and identifying clear consumers—so each GenAI use case builds on a solid, scalable foundation.
Core data product ingredients for GenAI
Below, we outline the key principles for making that happen, along with examples, roles, and how to handle incremental growth.
1. Discoverability
Implement a comprehensive data catalogue that documents what data exists, how it's structured, who owns it, and when it's updated. This catalogue should work in conjunction with—but not necessarily be derived from—any knowledge graphs built for specific GenAI use cases. While knowledge graphs excel at modelling domain-specific relationships, your data catalogue needs broader enterprise-wide coverage. Include the metadata and examples needed for generating SQL queries, as well as references for your vector database. (This is something we find particularly useful, for example when developing AI agents that autonomously generate SQL queries to search through databases. Curated, detailed metadata, including table schemas, column definitions, and relationships allow the agents to understand the structure and semantics of the databases.) Define a scheduled process to keep these inventories current, to ensure that new GenAI projects can easily discover existing datasets or embeddings, while avoiding unnecessary re-parsing or re-embedding of data that is already available.
2. Quality standards
This includes a range of processes. From reviewing PDF documents to remove or clarify checkboxes and handwritten text to checking chunk-level completeness for embeddings, consistent naming conventions, or standardized templates for prompt outputs. Involve domain experts to clarify which fields or checks are critical, and align those standards in your data catalogue. By enforcing requirements at the source, you prevent silent inconsistencies (like missing metadata or mismatched chunk sizes) from undermining your GenAI solutions later on.
3. Accessibility
GenAI models require consistent, reliable ways to retrieve information across your enterprise landscape—yet building a custom integration for every data source quickly becomes unsustainable. As an example, at a client a separate data repository was created—with its own API and security—to pull data from siloed systems. This is where the MCP comes in handy: by specifying a standard interface for models to access external data and tools, it removes much of the overhead associated with custom connectors. Not all vendors support MCP but adoption is growing (OpenAI for example provides it). So keep that in mind and avoid rushing into building custom connectors for every system. In sum, focus on building a solid RAG foundation for your most critical, large-scale enterprise data—where the return on investment is clear. For simpler or lower-priority use cases, it may be better to wait for MCP-ready solutions with built-in search, rather than rushing into one-off integrations. This balanced approach lets you meet immediate needs while staying flexible as MCP adoption expands. (We’ll dive deeper into MCP in our next blog post.)
4. Auditability
Log every step—when doing at least make sure to include knowledge graph updates to prompts, reasoning, and final outputs—so you can pinpoint which data, transformations, or model versions led to a given response. This is especially vital in GenAI, where subtle drifts (like outdated embeddings or older prompt templates) often go unnoticed until user trust is already compromised. From a compliance perspective, this is critical when GenAI outputs influence business decisions. Organizations may need to demonstrate exactly which responses were generated, what processing logic was applied, and which data was used at specific points in time—particularly in regulated industries or during audits. Ensure each logged event links back to a clear version ID for both models and data, and store these audit trails securely with appropriate retention policies to meet regulatory, privacy, and governance requirements.
5. Security & access control
Ensure appropriate role- and attribute-based access is enforced on all data sources accessed by your model, rather than granting blanket privileges. Align access with the end-user's identity and context, preventing the model from inadvertently returning unauthorized information. Be particularly vigilant about prompt injection attacks—where carefully crafted inputs manipulate models into bypassing security controls or revealing sensitive information. This remains one of GenAI's most challenging security vulnerabilities, as traditional safeguards can be circumvented through indirect methods. Consider implementing real-time checks, especially in autonomous agent scenarios, alongside an "LLM-as-a-judge" layer that intercepts and sanitizes prompts that exceed a user's permissions or exhibit malicious patterns. While no solution offers perfect protection against these threats, understanding the risk vectors and implementing defence-in-depth strategies significantly reduces your exposure. Resources like academic papers and technical analyses on prompt injection techniques can help your team stay informed about this evolving threat landscape.
6. LLMOps
A shared, organization-wide LLMOps pipeline and toolkit gives every GenAI project a stable, reusable foundation—covering everything from LLM vendor switching and re-embedding to common connectors and tool interfaces. Centralizing these resources eliminates ad-hoc solutions, promotes collaboration, and ensures proper lifecycle management. The result: teams can launch GenAI initiatives faster, apply consistent best practices, and still stay flexible enough to experiment with different models and toolchains.

Transform Generative AI potential into performance with robust data management
Whether you win or lose in your market may soon rely on having the best Generative AI capability - and the data management setup to support it. We can help you with this.
Explore our data management servicesThe takeaway: combine your GenAI implementation with proper data management
Implementing GenAI models and agentic systems isn’t just about prompting an LLM. It’s a data challenge and an architectural exercise. By starting with a high-impact use case, you secure immediate value and insights, while robust data management practices ensure you stay in control—maintaining quality and trust as AI spreads across your organization. By adopting these principles in your very first GenAI initiative, you avoid the trap of quick-win pilots that ultimately buckle under growing data complexity. Instead, each new use case taps into a cohesive, well-governed ecosystem—keeping your AI agents current, consistent, and secure as you scale.
Those who excel at both GenAI innovation and data management will be the ones to transform scattered, siloed information into a unified, GenAI-ready asset—yielding genuine enterprise value on a foundation built to last. If you haven’t already established data management standards and principles, don’t wait any longer—take a look at our blog posts on data management fundamentals part 1 and 2.
If you’d like to learn more about building a robust GenAI foundation, feel free to reach out to us.
This article was written by Daan Manneke, Data & AI Engineer at Rewire and Frejanne Ruoff, Principal at Rewire.
Managing change across interconnected data products is hard. A robust versioning strategy is key avoiding chaos and build a resilient, innovation-ready data ecosystem.
Many organizations are shifting towards federated data management setups in which data management is largely decentralized, enabling domains to develop their own data products. It’s an attractive model for large enterprises, promising reduced bottlenecks from central teams, faster innovation, and domain-specific decision-making.
In short: scalable data management!
However, decentralization introduces complexity, both technical and organizational. Take data interoperability as an example: as each domain builds and manages its own data products, integrating data across domains becomes increasingly complex. Different data models, formats, schemas and definitions make it hard to ensure easy data integration.
Other areas of concern include data security, discoverability and quality. As data products become more interconnected – where one product’s output feeds into another, especially across domains – another significant challenge emerges: managing changes made to these products. Without a well-coordinated versioning strategy, this can quickly lead to cascading disruptions in the data ecosystem.
In this blog post, we’ll explore why a versioning strategy is critical, why it is particularly complex in federated set-ups, and what makes a good data versioning strategy.
In a mesh of interconnected data products, a coordinated versioning strategy is critical
In a typical mesh of data products, these products don’t operate in isolation. They are usually interdependent, where one product’s input is another product’s output. This creates a complex web of relationships. When a change is made to one data product—whether it is an update, bugfix, or new feature release—it affects all downstream products (see below figure).
Figure 1: Potential consequences if one data product changes in a mesh of connected data products
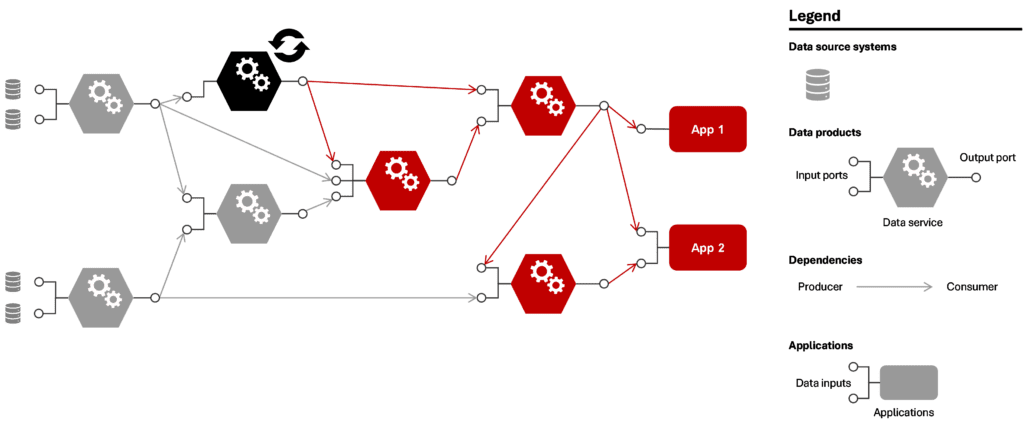
Even when changes happen infrequently, the interconnected nature of the system can cause the impact to snowball quickly. This is referred to as a cascading failure: a single change can spread through the system and cause unexpected behavior in products far removed from the original change. This makes it crucial to carefully manage dependencies and changes to maintain system stability.
Long-term consequence: loss of trust
Because relatively small changes can have such big impacts and lead to an unstable mesh, it can eventually erode trust in the entire system of data products. Over time, this lack of trust may push teams to revert to outdated methods like point-to-point connections or duplicating upstream data products, undermining the benefits of a decoupled (federated) approach.
What drives complexity in data product versioning in a federated set-up
Three aspects of data product versioning render the task complex. Let’s review them turn by turn.
1. Versioning is a significant technical challenge that goes beyond tracking data changes
Versioning presents a significant technical challenge. It’s not just about tracking changes in the data itself. It also involves managing the versioning of data transformation code, deployment code, access control policies, required packages, and supporting infrastructure. Extensive rollback capabilities are needed so that when something goes wrong, everything can be quickly and easily reverted back to a stable state.
How can we keep this mesh of interconnected data products healthy and stable while still allowing teams to innovate and release new updates?
2. More teams managing versions means greater complexity
In a federated set-up, data product versioning is no longer handled by a central team but by each domain independently. As a result, it becomes crucial to establish clear processes for version management across the organization. Without centralized oversight, coordinating large upgrades and ensuring alignment between domains can easily become unmanageable.
3. Innovation and business continuity are often at odds
Lastly, it can be difficult to balance innovation and stability. While decentralized approaches are often introduced to foster innovation and give teams greater freedom to ship new versions and iterate quickly, they must also ensure that changes don’t disrupt downstream consumers—or, in the worst case, compromise business continuity. This challenge grows as domains and interconnected data products proliferate.
Client example: In one organization, data products were initially built and maintained by a central data team. While this ensured stability, it also created long lead times and bottlenecks for new data needs. To speed up delivery, domain teams were allowed to develop their own data products. This worked well at first, but as teams began to use each other's outputs, this system quickly broke down: changes like renaming a column or modifying a metric caused dashboards to fail and models to crash, often without warning. With no shared versioning strategy in place, teams unintentionally disrupted each other almost weekly. The lack of transparency and coordination made the system nearly unmanageable. This example is not unique: it is typical of many organizations transitioning to a federated data model.
What makes a good data versioning strategy?
Given these complexities, organizations need to adopt a coordinated approach to data product versioning. Here we discuss three key components of a successful versioning strategy. Let’s review them one by one.
1. Unified versioning standards across domains
To avoid fragmentation and promote cross-domain data consumption, teams should follow consistent versioning guidelines that ensure clarity and interoperability across domains. These guidelines could include:
- Semantic versioning . This is a best practice versioning system adopted from software engineering, which distinguishes between major, minor, and patch updates. This approach data products updates to be labelled depending on the magnitude of the change and expected impact for consumers. As an example, semantic versioning for data products could look like the following:
- Patches involve bug fixes and performance optimizations.
- Minor updates introduce new capabilities, non-breaking to consumers, such as added columns and additional observability elements.
- Major updates are likely breaking to consumers, such as data type changes and definition changes.
- Unified communication mechanisms to notify stakeholders of upcoming changes, preferably automated when breaking changes are coming up.
- Clear documentation of changes, including expected impact on dependent data products, following the semantic versioning format and captured in changelogs.
The level of standardization should match the organization's complexity - too rigid frameworks can unnecessarily hinder innovation in smaller teams, while too loose approaches can lead to chaos in organizations with many domains.
2. Clear management of dependencies
In highly interconnected data ecosystems, dependency management must be explicit and transparent to prevent downstream failures. By giving downstream consumers visibility and time to adapt, organizations can prevent cascading failures and system instability. Key measures include:
- Transparency in data lineage. That is, ensuring that teams know where their data originates from, and which consumers depend on their data products.
- Structured rollout strategies such as parallel releases. This allows new and old versions to coexist for a transition period (a.k.a. the grace period) during which consumers have time to adapt before the old version is deprecated.
Client example: At a large financial institution, domain teams were unaware of the consumers of their data assets, or the use cases downstream of their data products. This resulted in slightly different versions of the same data being used throughout the organization. By adopting an approach that provided company-wide visibility into data lineage, and automatically updating it based on changes in data production and consumption, the client was able to untangle the ‘data spaghetti’ that had emerged from a lack of oversight.
3. Automation and tooling
Automated versioning is near-essential to make maintenance of data products efficient at scale, and error-free. Automation reduces human error, accelerates version rollouts, and ensures that versioning remains consistent and manageable even as the number of data products grows. Key elements include:
- Rollback capabilities to revert to stable versions when issues arise.
- Automated validation and testing to detect compatibility issues before deployment.
- Versioning as code, where versioning rules and policies are embedded in infrastructure and deployment pipelines.
- Developer tools that integrate with CI/CD pipelines, making versioning seamless for data engineers.
Client example: At one of our clients, we made the changelog an integral component in the lifecycle of data products. Through this approach, data products could not be altered without updating the changelog, making the changelog the source of truth for deployments and data product evolution. The CI/CD process for testing and deploying data products included analysis of the changelog, extracting the changes of the document, testing if these were following the intended versioning strategy (e.g. not skipping versions, checking if the documents includes information on the changes, analyzing whether it involves breaking changes), and if successful: deploying the data product, by changing the infrastructure and transformation logic according to the pre-defined deployment strategy. This approach improved the governance of data products in the organization and made it easier for data product builders to roll out changes.
Building a data readiness playbook
Market leaders reinvent and reorganize themselves around data. We can help you with this.
Conclusion
For organizations adopting federated data management, the way they approach data product versioning can be the deciding factor in the success or failure of their data mesh. A strong versioning strategy is more than just a technical necessity - it is the foundation for maintaining a stable yet flexible data ecosystem. The key is to strike the right balance: ensuring interoperability between domains, without hindering innovation. By setting clear standards, proactively managing data dependencies, and using automation, organizations can ensure that their federated data products evolve seamlessly - allowing teams to innovate while keeping the ecosystem resilient and reliable.
This article was written by Job van Zijl, Senior Data Engineer at Rewire and Tamara Kloek, Principal at Rewire.