Blog
Three design principles to create a flexible, reusable data architecture that grows with your organization.

You’ve got the prerequisites in place:
- A strategic AI roadmap. Check.
- The ability to develop data products. Check.
- Leadership alignment. Check.
The real question is: How can you build a data foundation that delivers value early without creating long-term problems, such as inconsistent metrics, fragile pipelines and technical debt.
It’s tempting to design the full data foundation upfront. In practice, this often leads to over-engineering, slow delivery, and frustrated stakeholders. A more effective approach is to start from value—while making deliberate design choices that allow the foundation to scale.
Why building a data foundation is so difficult
First, let's be clear about what we mean by a data foundation: A data foundation is the strategic layer of reusable, trusted data products, governance, and architecture that breaks down silos and turns raw data into actionable information aligned with business outcomes.
This enables organizations to accelerate analytics and AI use cases by providing consistent, high-quality data that supports both current needs and future growth. (More on data management fundamentals here.)
Building a data foundation is not just a technical exercise. Yes, you need platforms, pipelines, and integrations. But the real challenge is balancing (1) business impact, (2) trust in data, and (3) long-term scalability. Most organizations struggle because they oscillate between two common approaches to data foundation strategy.
Let's review them.
Top-down vs bottom-up data foundation approaches
Typically, one can consider starting top-down (i.e. from a value pool perspective) or bottom-up (i.e. from a source system perspective).
1. The top-down approach
It starts by addressing a specific business problem or use case.
For example: developing a price optimization tool for your sales team by stitching together CRM data, transaction history, and external market data into a customized pipeline built solely to serve that one application.
- Pro: strong business alignment. Data products are directly tied to measurable outcomes.
- Con: risk of fragmentation. Solutions become use-case specific, difficult to reuse, and often turn into silos.
2. The bottom-up approach
It starts by building the technical foundation first.
For example: unlocking all data from your ERP and CRM systems by ingesting and modeling large volumes of operational data before concrete business use cases have been defined.
- Pro: strong reusability. Source-aligned data products improve consistency and quality.
- Con: slow time to value. It’s unclear which use cases will be enabled, delaying impact and eroding trust.
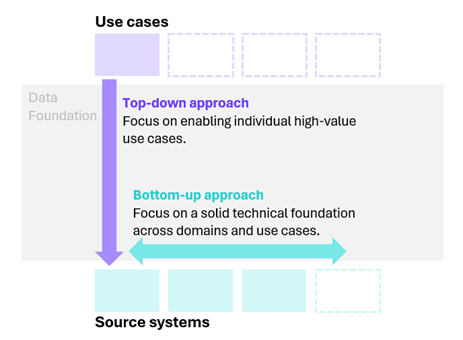
Figure 1. The top-down vs. bottom-up approach
3. The problem with either approach
Simply put, neither approach works well on its own:
- Lean too far top-down, and quick wins collapse because the underlying foundation cannot scale.
- Lean too far bottom-up, and you risk building a technically sound foundation that no one actively uses.
As a result, many organizations end up switching back and forth between these extremes, never fully unlocking the value of their data.
The solution: start top-down, but design for scale
To kickstart a data foundation effectively, we recommend a top-down, value-driven start combined with bottom-up design principles.
In practice, this means:
- Selecting priority use cases using a top-down approach, based on strategic importance and reuse potential.
- Applying scalable design principles when building data products, so today’s solution can evolve into tomorrow’s foundation.
This approach allows you to demonstrate value early while avoiding the common pitfall of creating one-off data solutions. The remaining risk is that a top-down start can still lead to fragmentation if design choices are made solely in service of the first use case.
The remainder of this article focuses on concrete design principles that mitigate these top-down pitfalls, as illustrated on the left-hand side of Figure 2. These principles ensure that value-driven data products can grow into a cohesive, reusable data foundation rather than a collection of isolated solutions.
Three design principles for scalable data products
As discussed in Data as a Product: Why Just Having Data Is Not Enough, data products are more than just data or pipelines. They encapsulate business logic, definitions, and assumptions. The way this logic is implemented determines whether a data product can evolve beyond its initial use case. The following design principles help ensure a top-down start remains sustainable.
1. Decouple data transformations to enable growth
Structure data products using clearly separated source → processing → sink layers so that ingestion, transformation, and delivery are explicitly isolated. This modular setup ensures that as new use cases emerge, individual parts of the data product can be extended, split, or reused—without rearchitecting the entire pipeline.
In practice, this means:
- Clearly separating source and sink logic, including all storage interactions and integrations with upstream or downstream data products.
- Isolating individual data transformation steps into distinct, composable blocks, each with a clear responsibility and output.
Why this matters:
- Enables faster creation and evolution of data products as scope expands.
- Keeps transformation logic readable, testable, and trustworthy for consuming teams.
2. Clearly document transformation logic and scope
Explicitly document the inputs, business rules, filters, and assumptions embedded in each data product so that its meaning and boundaries are unambiguous. This documentation should evolve together with the data product as scope and logic change.
In practice, this means:
- Listing all input sources and upstream data products the logic depends on.
- Describing applied business rules and filters, including rationale where relevant.
- Defining the intended scope and known exclusions to avoid misinterpretation by consumers.
Why this matters:
- Creates transparency around definitions and inclusions.
- Makes data products easier to extend, validate, and adapt as requirements evolve.
3. Design outputs for reuse across domains
Instead of optimizing outputs for a single business domain, deliberately design data product outputs to support multiple consuming domains from the start. This requires making consumption explicit and turning it into concrete design input.
In practice, this means:
- Identifying all potential consuming domains that are likely to use the data product now or in the near future.
- Capturing archetype consumption patterns and translating these patterns into detailed output requirements.
- Implementing these requirements in a consumer-aligned data model, defined through entities, attributes, and relationships that reflect shared business concepts rather than domain-specific needs.
Why this matters:
- Encourages reuse across the organization, accelerating new use case development.
- Reduces future rework by aligning outputs with real consumption needs upfront, making data products easier to extend and scale.
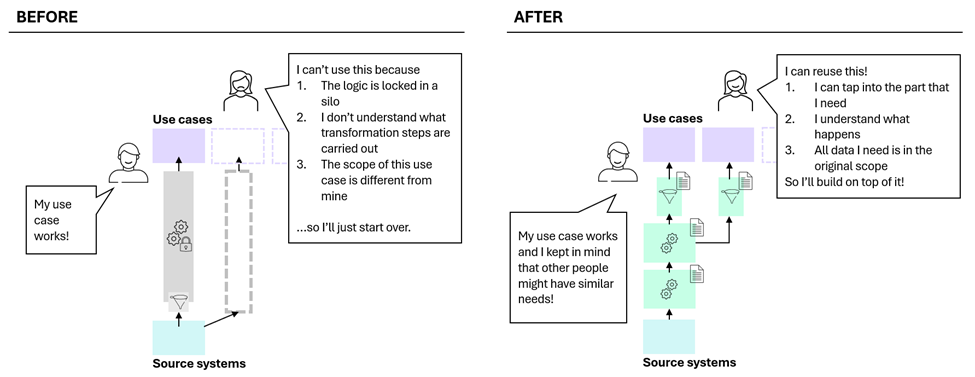
Figure 2. Before and after - the result of starting top-down while designing for scale.
Conclusion: building a data foundation that lasts
By starting with high-value use cases and applying scalable data product design principles, you can deliver immediate business impact without compromising the future. Done well, this approach results in a data foundation that grows organically from real business value rather than abstract architecture.
In short: don’t try to solve everything upfront—and don’t chase only quick wins either. The key to building a strong data foundation is delivering value today while deliberately designing for tomorrow.
This article was written by Bram van Koppen, Senior Data Engineer, and Phebe Langens, Data Scientist at Rewire.

Building your data capabilities, end-to-end
Our strategies elevate the performance of your data management from marginal or tactical results to transformational successes.
Explore our data management services


