Blog
Managing change across interconnected data products is hard. A robust versioning strategy is key avoiding chaos and build a resilient, innovation-ready data ecosystem.
Many organizations are shifting towards federated data management setups in which data management is largely decentralized, enabling domains to develop their own data products. It’s an attractive model for large enterprises, promising reduced bottlenecks from central teams, faster innovation, and domain-specific decision-making.
In short: scalable data management!
However, decentralization introduces complexity, both technical and organizational. Take data interoperability as an example: as each domain builds and manages its own data products, integrating data across domains becomes increasingly complex. Different data models, formats, schemas and definitions make it hard to ensure easy data integration.
Other areas of concern include data security, discoverability and quality. As data products become more interconnected – where one product’s output feeds into another, especially across domains – another significant challenge emerges: managing changes made to these products. Without a well-coordinated versioning strategy, this can quickly lead to cascading disruptions in the data ecosystem.
In this blog post, we’ll explore why a versioning strategy is critical, why it is particularly complex in federated set-ups, and what makes a good data versioning strategy.
In a mesh of interconnected data products, a coordinated versioning strategy is critical
In a typical mesh of data products, these products don’t operate in isolation. They are usually interdependent, where one product’s input is another product’s output. This creates a complex web of relationships. When a change is made to one data product—whether it is an update, bugfix, or new feature release—it affects all downstream products (see below figure).
Figure 1: Potential consequences if one data product changes in a mesh of connected data products
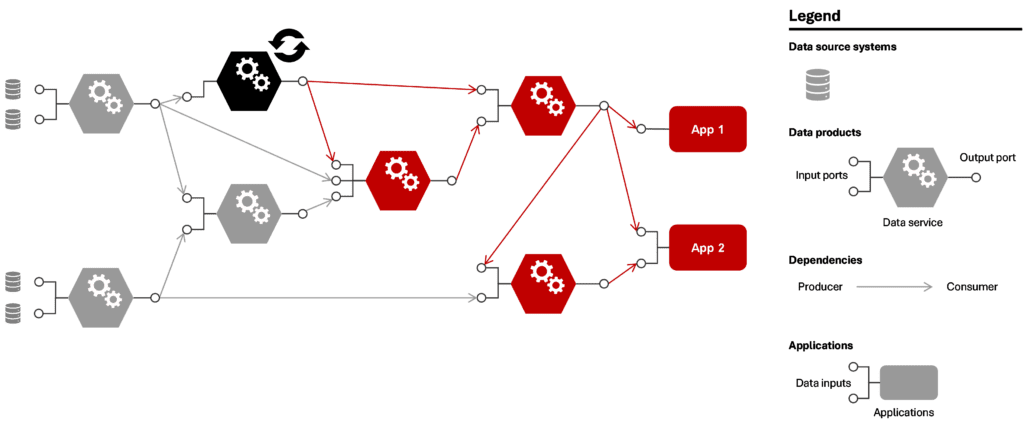
Even when changes happen infrequently, the interconnected nature of the system can cause the impact to snowball quickly. This is referred to as a cascading failure: a single change can spread through the system and cause unexpected behavior in products far removed from the original change. This makes it crucial to carefully manage dependencies and changes to maintain system stability.
Long-term consequence: loss of trust
Because relatively small changes can have such big impacts and lead to an unstable mesh, it can eventually erode trust in the entire system of data products. Over time, this lack of trust may push teams to revert to outdated methods like point-to-point connections or duplicating upstream data products, undermining the benefits of a decoupled (federated) approach.
What drives complexity in data product versioning in a federated set-up
Three aspects of data product versioning render the task complex. Let’s review them turn by turn.
1. Versioning is a significant technical challenge that goes beyond tracking data changes
Versioning presents a significant technical challenge. It’s not just about tracking changes in the data itself. It also involves managing the versioning of data transformation code, deployment code, access control policies, required packages, and supporting infrastructure. Extensive rollback capabilities are needed so that when something goes wrong, everything can be quickly and easily reverted back to a stable state.
How can we keep this mesh of interconnected data products healthy and stable while still allowing teams to innovate and release new updates?
2. More teams managing versions means greater complexity
In a federated set-up, data product versioning is no longer handled by a central team but by each domain independently. As a result, it becomes crucial to establish clear processes for version management across the organization. Without centralized oversight, coordinating large upgrades and ensuring alignment between domains can easily become unmanageable.
3. Innovation and business continuity are often at odds
Lastly, it can be difficult to balance innovation and stability. While decentralized approaches are often introduced to foster innovation and give teams greater freedom to ship new versions and iterate quickly, they must also ensure that changes don’t disrupt downstream consumers—or, in the worst case, compromise business continuity. This challenge grows as domains and interconnected data products proliferate.
Client example: In one organization, data products were initially built and maintained by a central data team. While this ensured stability, it also created long lead times and bottlenecks for new data needs. To speed up delivery, domain teams were allowed to develop their own data products. This worked well at first, but as teams began to use each other's outputs, this system quickly broke down: changes like renaming a column or modifying a metric caused dashboards to fail and models to crash, often without warning. With no shared versioning strategy in place, teams unintentionally disrupted each other almost weekly. The lack of transparency and coordination made the system nearly unmanageable. This example is not unique: it is typical of many organizations transitioning to a federated data model.
What makes a good data versioning strategy?
Given these complexities, organizations need to adopt a coordinated approach to data product versioning. Here we discuss three key components of a successful versioning strategy. Let’s review them one by one.
1. Unified versioning standards across domains
To avoid fragmentation and promote cross-domain data consumption, teams should follow consistent versioning guidelines that ensure clarity and interoperability across domains. These guidelines could include:
- Semantic versioning . This is a best practice versioning system adopted from software engineering, which distinguishes between major, minor, and patch updates. This approach data products updates to be labelled depending on the magnitude of the change and expected impact for consumers. As an example, semantic versioning for data products could look like the following:
- Patches involve bug fixes and performance optimizations.
- Minor updates introduce new capabilities, non-breaking to consumers, such as added columns and additional observability elements.
- Major updates are likely breaking to consumers, such as data type changes and definition changes.
- Unified communication mechanisms to notify stakeholders of upcoming changes, preferably automated when breaking changes are coming up.
- Clear documentation of changes, including expected impact on dependent data products, following the semantic versioning format and captured in changelogs.
The level of standardization should match the organization's complexity - too rigid frameworks can unnecessarily hinder innovation in smaller teams, while too loose approaches can lead to chaos in organizations with many domains.
2. Clear management of dependencies
In highly interconnected data ecosystems, dependency management must be explicit and transparent to prevent downstream failures. By giving downstream consumers visibility and time to adapt, organizations can prevent cascading failures and system instability. Key measures include:
- Transparency in data lineage. That is, ensuring that teams know where their data originates from, and which consumers depend on their data products.
- Structured rollout strategies such as parallel releases. This allows new and old versions to coexist for a transition period (a.k.a. the grace period) during which consumers have time to adapt before the old version is deprecated.
Client example: At a large financial institution, domain teams were unaware of the consumers of their data assets, or the use cases downstream of their data products. This resulted in slightly different versions of the same data being used throughout the organization. By adopting an approach that provided company-wide visibility into data lineage, and automatically updating it based on changes in data production and consumption, the client was able to untangle the ‘data spaghetti’ that had emerged from a lack of oversight.
3. Automation and tooling
Automated versioning is near-essential to make maintenance of data products efficient at scale, and error-free. Automation reduces human error, accelerates version rollouts, and ensures that versioning remains consistent and manageable even as the number of data products grows. Key elements include:
- Rollback capabilities to revert to stable versions when issues arise.
- Automated validation and testing to detect compatibility issues before deployment.
- Versioning as code, where versioning rules and policies are embedded in infrastructure and deployment pipelines.
- Developer tools that integrate with CI/CD pipelines, making versioning seamless for data engineers.
Client example: At one of our clients, we made the changelog an integral component in the lifecycle of data products. Through this approach, data products could not be altered without updating the changelog, making the changelog the source of truth for deployments and data product evolution. The CI/CD process for testing and deploying data products included analysis of the changelog, extracting the changes of the document, testing if these were following the intended versioning strategy (e.g. not skipping versions, checking if the documents includes information on the changes, analyzing whether it involves breaking changes), and if successful: deploying the data product, by changing the infrastructure and transformation logic according to the pre-defined deployment strategy. This approach improved the governance of data products in the organization and made it easier for data product builders to roll out changes.

Building a data readiness playbook
Market leaders reinvent and reorganize themselves around data. We can help you with this.
Conclusion
For organizations adopting federated data management, the way they approach data product versioning can be the deciding factor in the success or failure of their data mesh. A strong versioning strategy is more than just a technical necessity - it is the foundation for maintaining a stable yet flexible data ecosystem. The key is to strike the right balance: ensuring interoperability between domains, without hindering innovation. By setting clear standards, proactively managing data dependencies, and using automation, organizations can ensure that their federated data products evolve seamlessly - allowing teams to innovate while keeping the ecosystem resilient and reliable.
This article was written by Job van Zijl, Senior Data Engineer at Rewire and Tamara Kloek, Principal at Rewire.



