Blog
Why combining Retrieval-Augmented Generation with Knowledge Graphs holds transformative potential for AI.

Google it! How many times have you said that before? Whether you're settling a friendly debate or hunting for that perfect recipe, Google is our go-to digital oracle. But have you ever wondered what happens behind that simple search bar? At the heart of Google's search magic lies something called a Knowledge Graph—a web of interconnected information that's revolutionizing how AI understands our queries. And guess what? This same technology, along with RAG (Retrieval-Augmented Generation), is transforming how businesses handle their own data. In this article we’ll explore the journey from data to insight, where RAG and Knowledge Graphs are the stars of the show!
The power of RAG: enhancing AI's knowledge base
Retrieval-Augmented Generation, or RAG, is a fascinating approach that's changing the game in AI-powered information retrieval and generation. But what exactly is RAG, and why is it causing such excitement in the AI community?
At its core, RAG addresses a fundamental limitation in GenAI models like ChatGPT: their knowledge is strictly bounded by their training data. Consider this: if you ask ChatGPT's API (which doesn’t have the web search capability) about the 2024 Euro Cup winner, it can’t give you the answer as this event occurred after its last knowledge or training update. The same applies to company-specific queries like "What were our Q3 financial results?" The model inherently cannot access such private, domain-specific information because it's not part of its training data. This inability to access real-time or specialized information significantly limits the range of responses these models can generate.
RAG offers a solution by combining user prompts with relevant information retrieved from external sources, such as proprietary databases or real-time news feeds. This augmented input enables GenAI models to generate responses that are both contextually richer and up-to-date, allowing them to answer questions even when their original training data doesn't contain the necessary information. By bridging the gap between AI training and the dynamic world of information, RAG expands the scope of what GenAI can achieve, especially for use cases that demand real-time relevance or access to confidential data.
How does RAG work its magic?
Now that we've established how RAG addresses the limitations of traditional GenAI models, let’s break down the four essential steps to getting RAG to work: data preparation, retrieval, augmentation, and generation.
Like most AI systems, effective RAG is dependent on data: it requires the external data to be prepared in an accessible way that is optimized for retrieval. When a query is made, relevant information is retrieved and augmented to this query. The model finally generates a well-informed response, leveraging both its natural language capabilities and the retrieved information. Here's how these steps unfold.
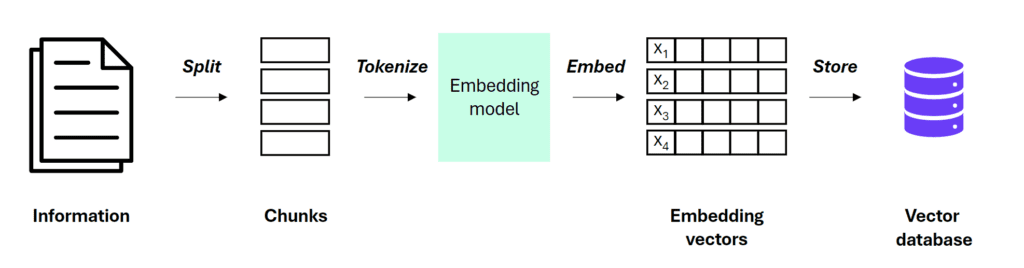
1. Data Preparation: This crucial first step involves parsing raw input documents into an appropriate format (usually text) and splitting them into manageable chunks. Each text chunk is converted into a high-dimensional numerical vector that encapsulates its meaning, called an embedding. These embeddings are then stored in a vector database, often with an index for efficient retrieval.
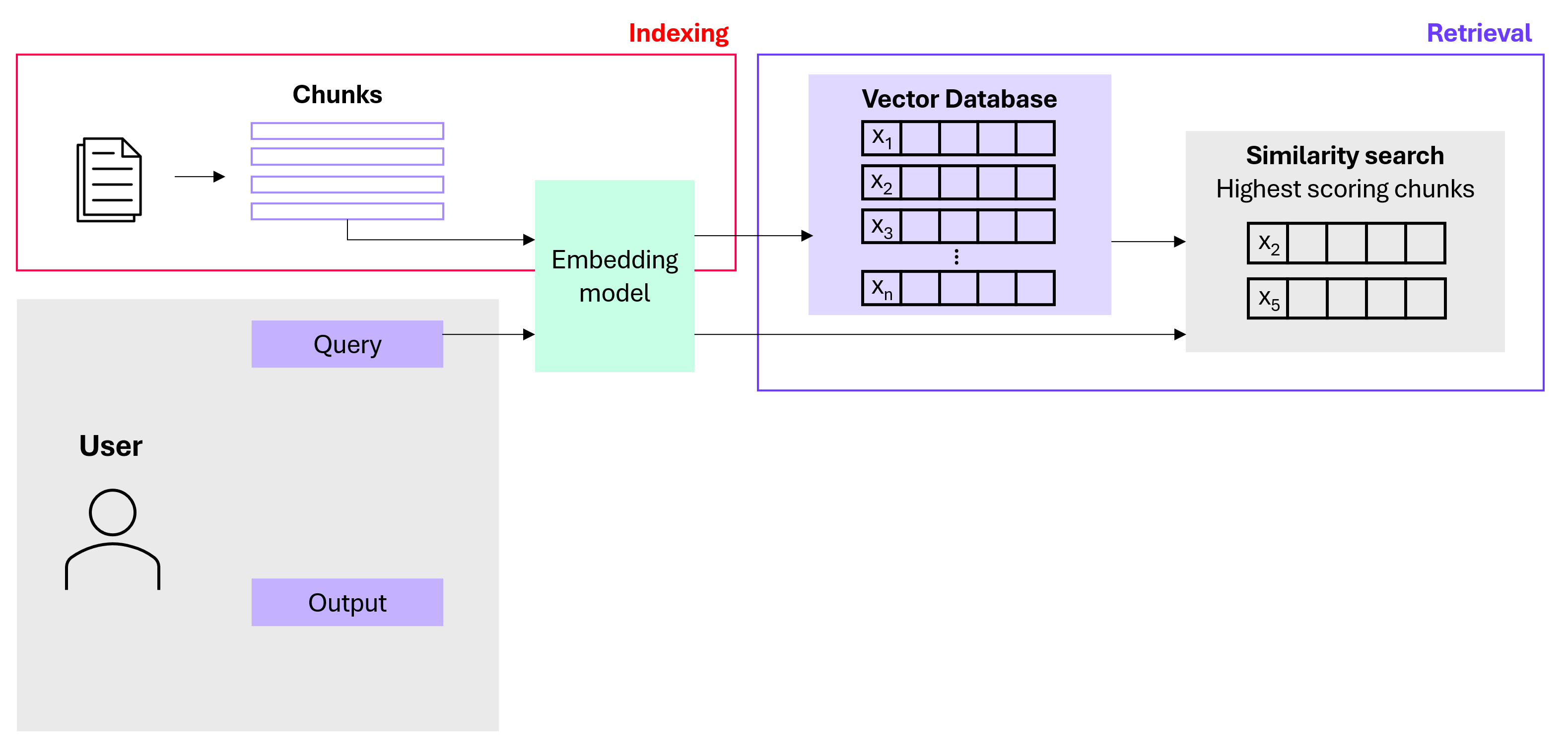
2. Retrieval: When a user asks a question, RAG embeds the query (with the same embedding model that was used to embed the original text chunks), searches the database for similar vectors (similarity search) and then retrieves the most relevant chunks.
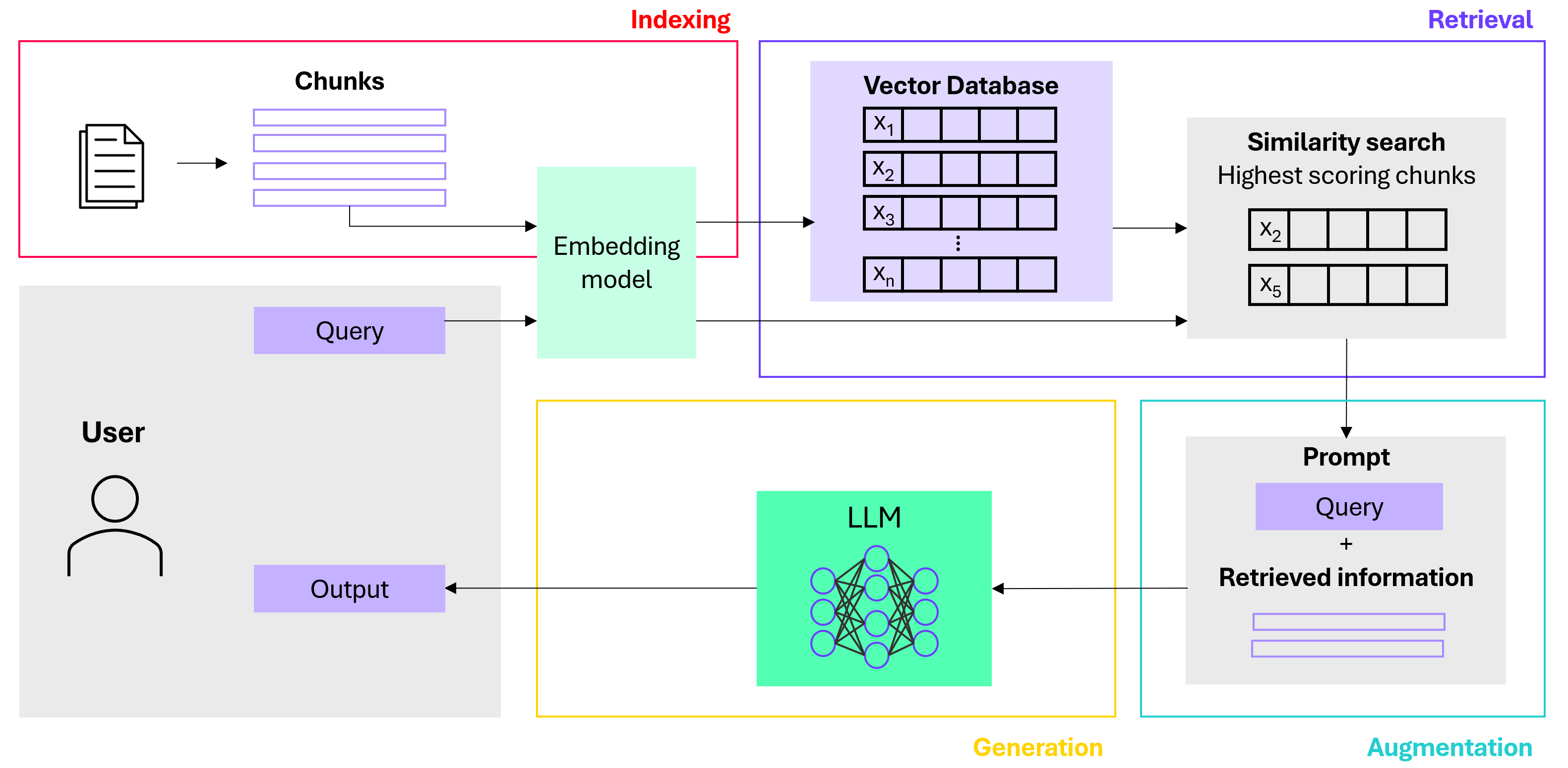
3. Augmentation: The most relevant results from the similarity search are used to augment the original prompt.
4. Generation: The augmented prompt is sent to the Large Language Model (LLM), which generates the final response.
The beauty of RAG is that it doesn't fundamentally change the model's behavior or linguistic style. Instead, it enhances the model's knowledge base, allowing it to draw upon a vast repository of information to provide more informed and accurate responses.
While RAG has numerous applications, its impact on business knowledge management stands out. In organizations with 50+ employees, vital knowledge is often scattered across systems like network drives, SharePoint, S3 buckets, and various third-party platforms, making it difficult and time-consuming to retrieve essential information.
Now, imagine if finding company data was as easy as a Google search or asking ChatGPT. RAG makes this possible, offering instant, accurate access to everything from project details to financial records. By connecting disparate data sources, RAG centralizes knowledge, streamlines workflows and turns scattered information into a strategic asset that enhances productivity and decision-making.
Knowledge Graphs: mapping the connections
While RAG excels at retrieving relevant information, it doesn’t always capture the broader context of interconnected data. In complex business environments, where relationships between projects, departments, and clients are crucial, isolated facts alone may not tell the full story. This is where RAG falls short: it retrieves data, but it doesn’t always "understand" how these pieces fit together. Here, Knowledge Graphs (KGs) come in, mapping connections between entities to create a structured, context-rich network of relationships that deepens AI’s understanding.
How do Knowledge Graphs work?
A Knowledge Graph (KG) is a network of interconnected concepts, where nodes represent entities (e.g., people, projects, or products), and edges show the relationships between them. KGs are especially powerful because they can easily incorporate new information and relationships, making them adaptable to changing knowledge.
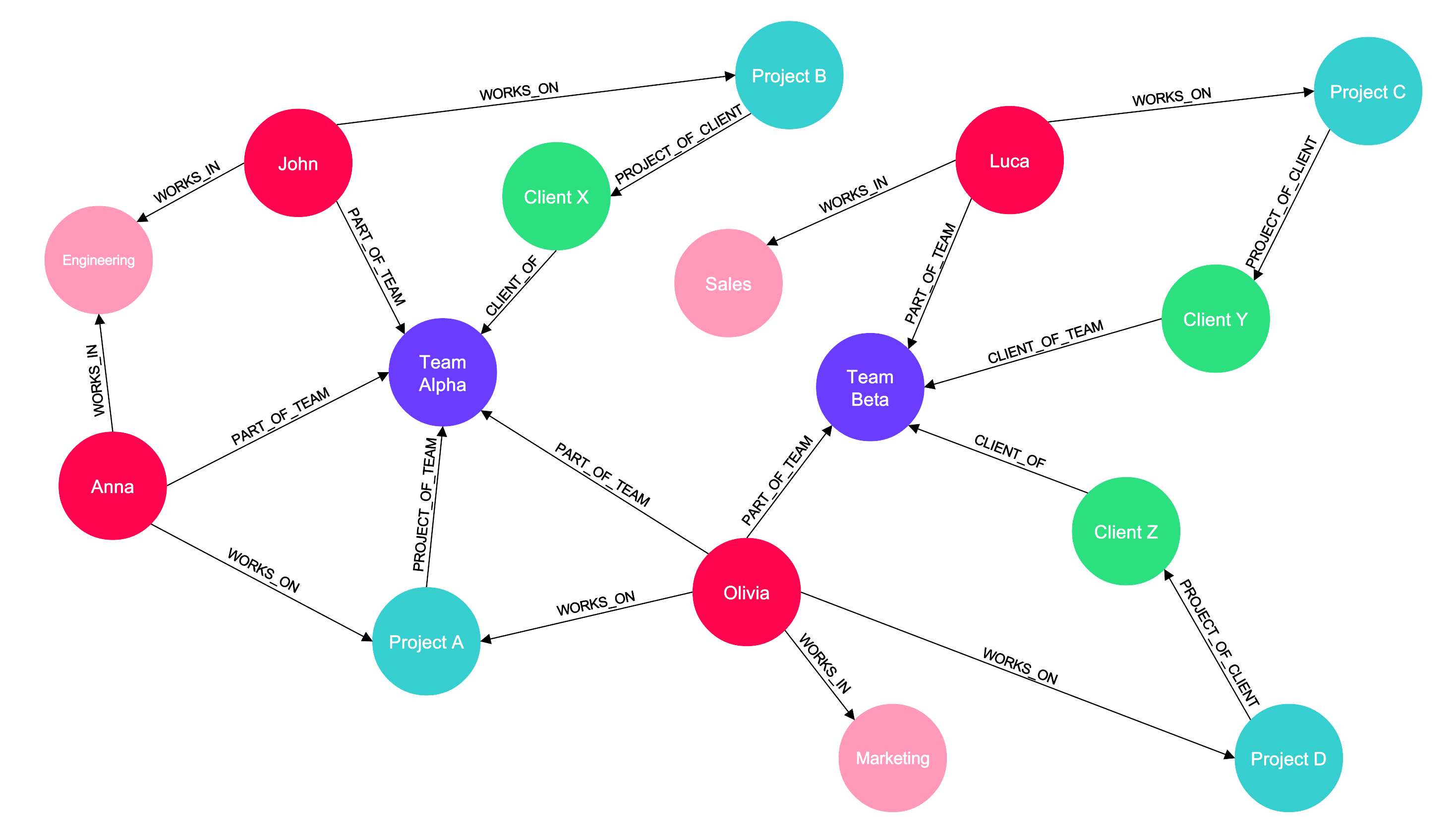
For businesses, a unified view of their data is invaluable. Knowledge Graphs organize complex relationships between employees, teams, projects, and departments, transforming scattered data into a structured network of meaningful connections. This structured approach empowers GenAI by enabling more intelligent, context-aware outputs based on deep, interconnected insights.
Imagine a GenAI-powered workflow: when a user poses a question, the system translates it into a query, perhaps leveraging a graph query language like Gremlin. The Knowledge Graph responds by surfacing relevant relationships—such as past interactions with a client or the expertise of specific team members. GenAI then synthesizes this enriched data into a clear, actionable response. Whether HR is identifying the ideal candidate for a project or sales is retrieving a client's complete history, integrating KGs into AI workflows allows businesses to extract these interconnected insights.
Bringing knowledge graphs and RAG together: introducing GraphRAG
Both RAG and Knowledge Graphs tackle a fundamental challenge in AI: enabling machines to understand and use information more like humans do. Each technology excels in different areas—RAG is particularly strong at retrieving unstructured, text-based information, while Knowledge Graphs are powerful for organizing and connecting information in meaningful ways. Notably, Knowledge Graphs can now also incorporate unstructured data processed by LLMs, allowing them to reliably retrieve and utilize information that was originally unstructured. This synergy between RAG and Knowledge Graphs creates a complementary system capable of managing diverse information types, making their integration especially valuable for internal knowledge management in businesses, where a wide range of data must be effectively utilized.
Here's how this powerful combination works:
1. Building the Knowledge Graph with RAG: We start by setting up a Knowledge Graph based on the relationships in the company's data, using RAG right from the start. This process involves chunking all internal documents and embedding these chunks. By applying similarity searches on these embeddings, RAG uncovers connections within the data, helping to shape the structure of our Knowledge Graph as it is being built.
2. Connecting Documents to the Graph: Once we have our Knowledge Graph, we connect the embeddings of the chunked documents to the corresponding end nodes. For instance, all embedded documents regarding Project A are connected to the Project A node in the graph. The result is a rich Knowledge Graph where some nodes are linked to embedded chunks of internal documents.
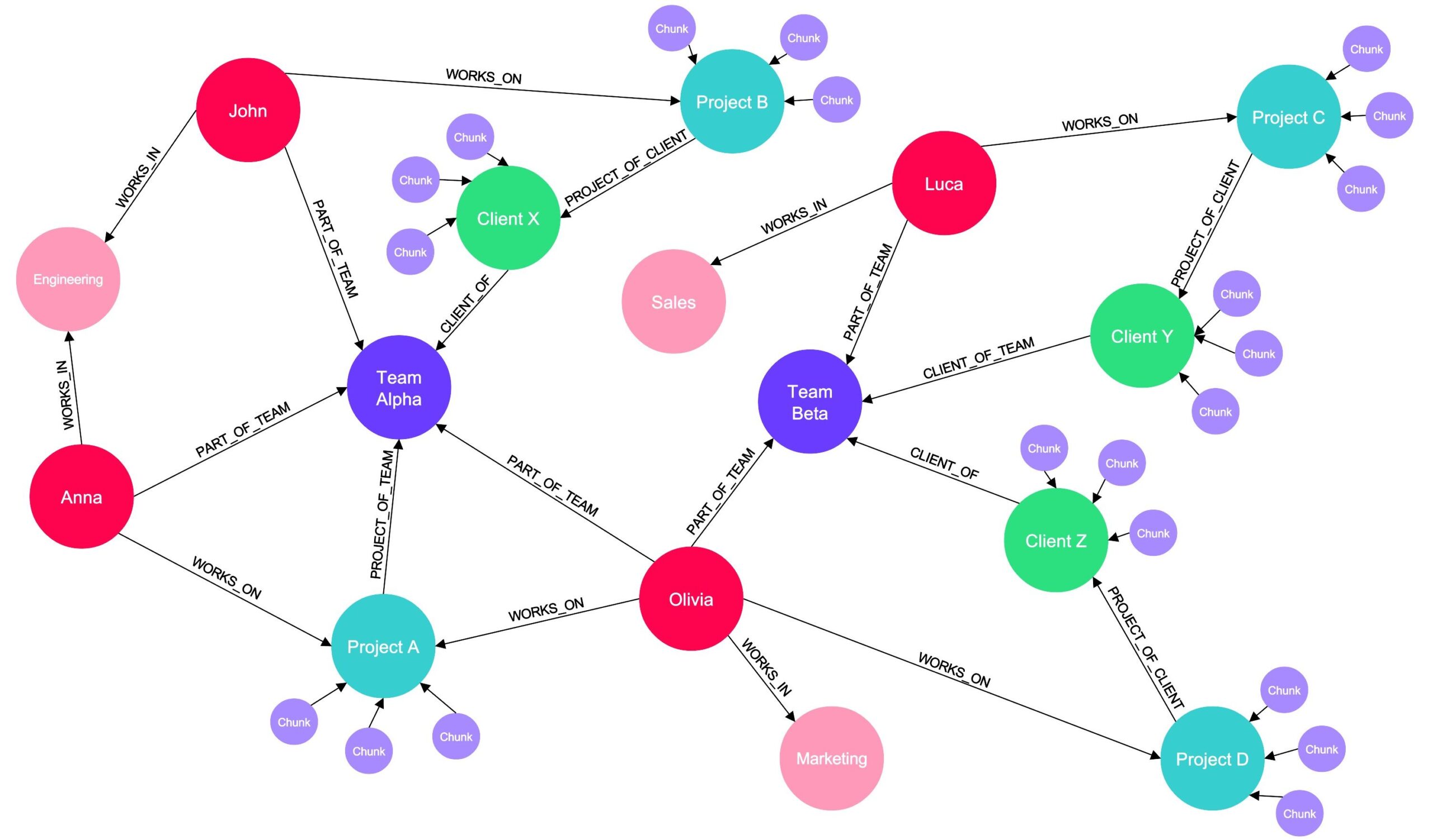
3. Leveraging RAG for Complex Queries: This is where RAG again comes into play. For questions that can be answered based purely on the Knowledge Graph structure, we can quickly provide answers. But for queries requiring detailed information from documents, we use RAG:
- We navigate to the relevant node in the Knowledge Graph (e.g., Project A).
- We retrieve all connected embeddings (e.g., all embedded chunks connected to Project A).
- We perform a similarity search between these embeddings and the user's question.
- We augment the original user prompt with the most relevant chunks (use database keys to obtain the chunks corresponding to the relevant embeddings) .
- Finally, we pass this augmented prompt to a LLM to generate a comprehensive answer.
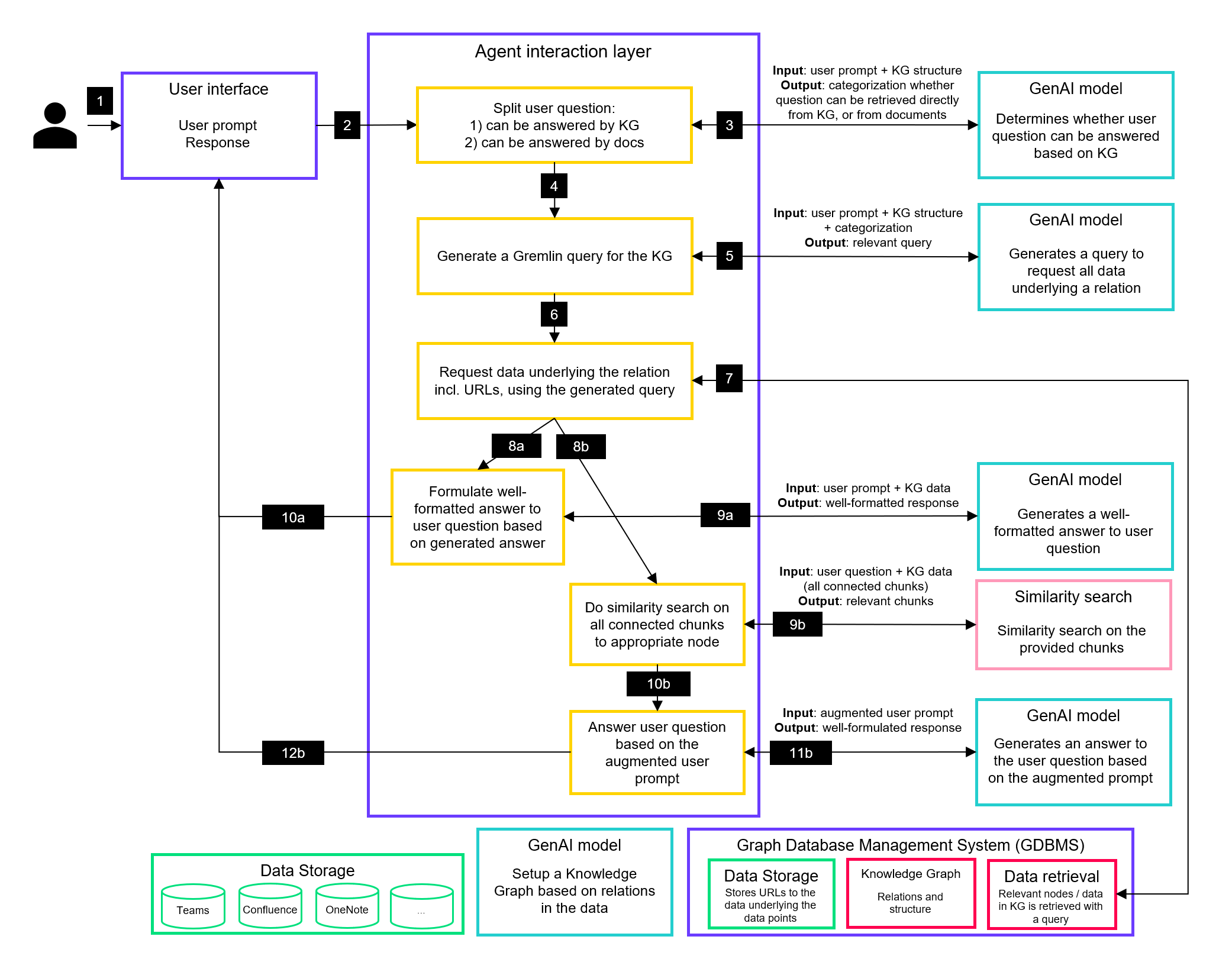
This hybrid approach combines the best of both worlds. The Knowledge Graph offers a structured overview of the company's information landscape, enabling quick responses to straightforward queries while also efficiently guiding RAG to the most relevant subset of document chunks. This significantly reduces the number of chunks involved in similarity searches, optimizing retrieval. Meanwhile, RAG excels at performing deeper, more detailed searches when necessary, providing comprehensive answers without the computational burden of scanning all documents for each query. Together, they create a more efficient, scalable, and intelligent system for handling business knowledge.
Unlocking actionable insights: the future with RAG and knowledge graphs
Practically speaking, RAG and Knowledge Graphs revolutionize how we interact with data by making information both accessible and deeply connected. It’s like searching your company’s entire database as effortlessly as using Google, but with precise, up-to-date answers. The impact? Streamlined workflows, faster decision-making, and the discovery of connections you may not have realized were there.
The impact of combining RAG with Knowledge Graphs extends far beyond basic knowledge management, reshaping various industries through its ability to link real-time, context-aware insights with complex data structures. In customer service, this technology could enable support bots to deliver highly personalized assistance by connecting past interactions, product histories, and troubleshooting steps into a seamless, context-aware experience. The financial sector benefits from enhanced fraud detection capabilities, as GraphRAG can map intricate transactional relationships and retrieve specific records for thorough investigation of suspicious patterns. Additionally, healthcare organizations can use the technology's potential to revolutionize patient care by creating comprehensive connections between diagnoses, treatments, and real-time medical records, while simultaneously matching patients with relevant clinical trials based on their detailed medical histories. In the terms of supply chain management, GraphRAG can empower teams with real-time disruption alerts and relationship mapping among suppliers and inventory, enabling more agile responses to sudden changes. And as a last example, market intelligence teams may gain a significant advantage through dynamic insights that link competitor data, emerging trends, and current information, facilitating proactive strategic planning.
By combining retrieval and relationship mapping, RAG and Knowledge Graphs turn complex data into actionable insights—making it easier than ever to find exactly what you need, when you need it.

Turning Generative AI potential into bottom line impact
Our strategies enable you to harness generative AI, moving beyond marginal or tactical gains to achieve transformational success.
Explore our Generative AI servicesThe challenge of building GraphRAG: unlocking data’s potential with precision and scalability
While combining RAG with KGs holds transformative potential, implementing this hybrid solution introduces significant technical and organizational challenges. The core complexity lies in seamlessly integrating two sophisticated systems—each with unique infrastructures, requirements, and limitations—into a unified, scalable architecture that can evolve with growing data demands. Other key challenges include:
- Data Consistency and Integration: Consolidating data from multiple sources like SharePoint, S3, and internal databases requires a robust integration framework to maintain cross-platform consistency, data integrity, and efficient real-time updates with minimal latency.
- Graph Structure and Adaptability: Designing a Knowledge Graph that accurately models an organization’s data relationships requires a deep understanding of interconnected entities, processes, and history. This graph must be adaptable to incorporate new data and evolving relationships, necessitating rigorous planning and proactive maintenance.
- System Optimization for Real-Time Performance: For large-scale deployments, the system must support complex queries with minimal latency. Achieving this balance requires an optimized allocation of computational resources to ensure high performance, especially during real-time retrieval and similarity searches.
- Security and Access Control: Integrating RAG with Knowledge Graphs requires careful handling of sensitive data, including strong access controls, clear permission settings, and regulatory compliance to keep proprietary information secure and private. For example, a knowledge management system should restrict access to sensitive files—such as confidential financial reports or HR documents—so that employees see only information they are authorized to access.
By addressing these challenges through a structured, security-focused approach, organizations can unlock the full potential of their data, building a scalable foundation for advanced insights and innovation.
This article was written by Anna Thoolen and Mirte Pruppers, Data Scientists at Rewire, as well as Simon Koolstra, Principal at Rewire.




![[Video] AI innovation and regulation beyond human comprehension](https://rewirenow.com/app/uploads/2024/10/Stefan-Leijnen_16-May-2024-1-1024x695.png)