Data leaders from across industries gathered to explore how to scale AI initiatives, navigate legacy systems, and unlock long-term value through strategic data management.
Last week, Rewire welcomed senior data leaders for the second edition of the Data Leadership Roundtable. Held at our Amsterdam office, the event brought together executives from a broad range of organizations – Shell, Rabobank, Heineken, AFM, KPN, Terberg, a.s.r. and many more – for an open exchange on two urgent challenges in data strategy: how to balance investment trade-offs to unlock value, and how to scale AI and data initiatives in environments dominated by legacy systems.

Industry leaders at the table.
The morning began with a plenary perspective from Rewire Partner Helen Rijkes, who reflected on the dramatic evolution of data work—from manual reporting using SPSS over 15 years ago to today's modern data environments, shaped by the shift toward domain-based data ownership and emerging technologies such as GenAI. She emphasized that the challenge isn’t building isolated use cases, but rather scaling them into sustained, organization-wide value. Success, she argued, comes from strategic balancing between consistent capability building and scaling value cases while embedding secure data access policies at scale.

Helen Rijkes, Partner at Rewire, reflecting on the evolution of data management in recent years.
The plenary was followed by a panel discussion featuring Annemarie de Beer (AFM), Gijs Thieme (KPN), Maarten Kramer (a.s.r.), and Sam van Kesteren (Royal Terberg Group). Their conversation explored how organizations balance central and decentralized approaches to data, with many agreeing that centralized data science teams help avoid fragmentation, while local business ownership is critical for adoption. They also examined the ongoing tension between building versus buying solutions, noting that while building is attractive for strategic control and internal talent, buying can accelerate implementation—provided there's clarity on vendor limitations and alignment with business needs. Finally, the panel addressed legacy systems, emphasizing that successful transformation requires not only technical migration but also strong change management and alignment across business and IT.

Annemarie, Gijs, Maarten, and Sam share their perspectives on common data strategy challenges
After the panel, the group split into four breakout discussions, each diving deeper into the practical realities of leading data strategy in complex environments. In one group, participants discussed the evolving role of data scientists, the importance of aligning platform decisions with long-term strategy, and the challenge of ensuring responsible access to both structured and unstructured data. Another group focused on why so many AI initiatives get stuck in the proof-of-concept phase, concluding that without the right infrastructure, skills, and business engagement, even promising pilots can fail to scale. A third group explored how to move from compliance-driven data management to a value-driven model, especially in regulated industries, while also grappling with new ethical questions introduced by AI. And in the fourth group, participants reflected on the importance of embedding AI into day-to-day decision-making, emphasizing that adoption—not just technical readiness—is what ultimately drives success.

Sharing challenges. Shaping solutions. Together.
Throughout the day, one message came through clearly: the real challenge in data and AI transformation isn’t just technical—it's organizational. Success depends on bridging silos, aligning stakeholders, embedding data into business processes, and building the trust and capabilities needed to move from experimentation to impact.
We’re incredibly grateful to all participants for their insights and participation. The conversations reaffirmed the importance of community in tackling the complex challenges when executing your data strategy in the Data & AI landscape of today. We look forward to continuing that dialogue in future roundtables.
How business leaders are turning AI ambition into operational reality
Last week we had the honor of welcoming industry leaders and researchers to Rewire LIVE 2025 in Frankfurt — for a day of practical insights on scaling data and AI, from vision to value at scale. With a packed agenda of keynotes, case studies, and mastermind sessions, the event zeroed in on one of the toughest challenges in enterprise AI today: how to bridge the last mile — turning promising pilots into production-grade, scalable, and trusted AI systems.
We know the answer but not the question
Rewire partner Christoph Sporleder thus opened the day by challenging common strategic pitfalls in AI adoption. Whether taking an exploratory, foundational, or holistic approach, many organizations struggle to operationalize at scale due to mismatched expectations, over-engineering, or governance complexities. His conclusion on breaking it down, balancing the transformation dimensions and going the full mile towards scale were picked up in the the powerful keynote of Simone Menne, Lufthansa’s former first female CFO. She reminded us that the real challenge of AI isn’t finding answers — it’s asking the right questions. Drawing from The Hitchhiker’s Guide to the Galaxy and her experience in leadership, Simone Menne spoke to the cultural and psychological hurdles that slow AI adoption. To overcome this we need to confront fear, foster curiosity, and prioritize education, governance, and collaboration across sectors to close the gap between potential and execution.
Dr. Peter Bärnreuther from Munich Re walked us through the rapidly growing domain of AI risks, from legal liabilities and IP issues to model drift and data bias. With over 200 AI-related lawsuits already filed globally, the urgency for transparent, testable, and auditable AI systems is mounting, and Munich Re is leading the way in also providing insurance products for AI. Nikhil Srinidhi, Partner at Rewire, illustrated the growing chasm between AI ambition and data readiness. In his talk, “Mind the Data Gap,” he highlighted the widening divide caused by poor data quality, fragmented ownership, and an expanding AI vendor landscape. His takeaway: scaling GenAI means scaling data maturity — and doing it across architecture, culture, and capability. Shannon Kehoe of QuantPi went on to emphasize that trust in AI starts with predictability and transparency. She introduced a model-agnostic platform that tests AI solutions across dimensions and presents results clearly for diverse stakeholders — from data scientists to regulators. Loïc Tilman of Elia Group shared what it takes to scale AI within a critical infrastructure operator. From evolving legacy systems to upskilling teams and ensuring sovereignty in the IT infrastructure, his talk made it clear: even in high-stakes environments, digital, data and AI transformation isn’t a luxury — it’s a necessity.
AI masterminds: defining real solutions to real challenges
The event also included interactive sessions, where Lu Yu of Novo Nordisk, Dr. Pierre Fischer of Roche and Dr. Martin Paschmann of Douglas shared real-world case studies. Participants dissected challenges ranging from siloed systems to frontline adoption. Solutions focused on data culture, internal champions, and aligning science with business needs. In one mastermind session, participants unpacked how to define the value of data products — from use-case fit and quality to cloud cost savings, time-to-insight, and user satisfaction. A key insight: value must be seen through multiple lenses — technical, financial, and strategic — and agreed upon by data, finance, and business stakeholders.

Creating a blueprint for AI Transformation
Our strategies elevate the performance of your AI applications from marginal or tactical results to unequivocal, transformational successes.
Discover our Data & AI StrategyPanel discussion: scaling AI responsibly
The day concluded with a rich panel featuring Eberhard Schnebel (Goethe University Frankfurt / Commerzbank), Dr. Stefan Rose (University of Cologne), and Paola Daniore (EPFL Lausanne), moderated by Damien Deighan, Editor of the Data and AI magazine. Topics included the privacy paradox between academia and industry; the social psychology of AI interaction in teams; Trust-building through transparency and governance; The ethical design of emotionally resonant AI systems. Their message: AI adoption is about more than models. It’s about culture, behavior, and values — and how we ensure they evolve together.
Final thoughts
Rewire LIVE 2025 reinforced a shared truth: next to data and technology, AI is a leadership challenge. The ideas, stories, and solutions shared in Frankfurt revealed a deep appetite for actionable, scalable, and human-centered approaches to Data & AI.
We’re grateful to all speakers, participants, and partners who made the day a success. Let’s keep building — together.
Want to learn more about upcoming Rewire events? Visit the Rewire events page here.
A handful of principles will set you up for success when bringing GenAI to enterprise data.
As highlighted in our 2025 Data Management Trends report, the rapid evolution of LLMs is accelerating the shift of GenAI models and agentic systems from experimental pilots to mission-critical applications. Building a proof of concept that taps a single data source or uses a few prompts is relatively simple. But delivering real business value requires these models to access consistent, high-quality data—something often trapped in silos, buried in legacy systems, or updated at irregular intervals.
To scale from pilot to production, organizations need a more structured approach—one grounded in solid data management practices. That means integrating with enterprise data, enforcing strong governance, and ensuring continuous maintenance. Without this foundation, organizations risk stalling after just one or two operationalized GenAI use cases, unable to scale or accommodate new GenAI initiatives, due to persistent data bottlenecks. The good news is that those early GenAI implementation efforts are the ideal moment to confront your data challenges head-on and embed sustainable practices from the start.
How, then, can data management principles help you build GenAI solutions that scale with confidence?
In the sections that follow, we’ll look at the nature of GenAI data and the likely challenges it poses in your first value cases. We’ll then explore how the right data management practices can help you address these challenges—ensuring your GenAI efforts are both scalable and future-proof.
Understanding the nature of GenAI data
GenAI data introduces a new layer of complexity that sets it apart from traditional data pipelines, where raw data typically flows into analytics or reporting systems. Rather than dealing solely with structured, tabular records in a centralized data warehouse, GenAI applications must handle large volumes of both structured and unstructured content—think documents, transcripts, and other text-based assets—often spread across disparate systems.
To enable accurate retrieval and provide context to the model, unstructured data first be made searchable. This typically involves chunking the content and converting it into vector embeddings or exposing it via a Model Context Protocol (MCP) server, depending on the storage provider (more on that later). Additional context is increasingly delivered through metadata, knowledge graphs, and prompt engineering, all of which are becoming essential assets in GenAI architectures. Moreover, GenAI output often extends beyond plain text. Models may generate structured results—such as function calls, tool triggers, or formatted prompts—that require their own governance and tracking. Even subtle variations in how text is chunked or labeled can significantly influence model performance.
Because GenAI taps into a whole new class of data assets, organizations must treat it differently from standard BI or operational datasets. This introduces new data management requirements to ensure that models can reliably retrieve, generate, and act on timely information—without drifting out of sync with rapidly changing data. By addressing these nuances from the outset, organizations can avoid performance degradation, build trust, and ensure their GenAI solutions scale effectively while staying aligned with business goals.
Start smart: consider data representability
Selecting your first GenAI value case to operationalize is a critical step—one that sets the tone for everything that follows. While quick experiments are useful for validating a model’s capabilities, the real challenge lies in integrating that model into your enterprise architecture in a way that delivers sustained, scalable value.
Choosing the right value case requires more than just identifying an attractive opportunity. It involves a clear-eyed assessment of expected impact, feasibility, and data readiness. One often overlooked but highly valuable criterion is data representability: how well does the use case surface the kinds of data challenges and complexities you’re likely to encounter in future GenAI initiatives?
Your first operationalized value case is, in effect, a strategic lens into your data landscape. It should help you identify bottlenecks, highlight areas for improvement, and stress-test the foundations needed to support long-term success. Avoid the temptation to tackle an overly ambitious or complex use case out of the gate—that can easily derail early momentum. Instead, aim for a focused, representative scenario that delivers clear early wins while also informing the path to sustainable, scalable GenAI adoption.
Don’t get stuck: Answer these critical data questions
The targeted approach described above delivers the early tangible win needed to get stakeholder buy-in—and, more critically, it exposes underlying data issues that might otherwise go unnoticed. Here are typical data requirements for your first GenAI use case, along with the key challenge they create and core questions you’ll need to answer.
| Requirement | Challenge | Key questions |
| Integrated information | Previously untapped information (for example, pdf documents), is now a key data source and must be integrated with your systems. | * Where is all this data physically stored? Who maintains ownership of each source? * Do you have the necessary permissions to access them? * Does the data storage tool provide a MCP server to interact with the data? |
| Searchable knowledge system | Searchable documents must be chunked, embedded, and updated in a vector database—or exposed via an MCP server—creating new data pipeline and infrastructure demands. | * Can you find a reliable embedding model for capturing the nuances in your business? * How frequently must you re-embed to handle updates? * Are the associated costs manageable at scale? |
| Context on how data is interconnected | Reasoning capabilities require explicitly defined relationships—typically managed through a knowledge graph. | * Is your data described well enough to construct such a graph? * Who will ensure these relationships and definitions stay accurate over time? |
| Retrieval from relational databases by an LLM | Models need rich, well-documented metadata to understand and accurately query relational data. | * Are vital metadata fields consistent and detailed? * Do you have the schemas and documentation required for the model to navigate these databases effectively? |
| Defining prompts, output structures and tool interface | Prompts, interfaces, and outputs must be reusable, versioned, and traceable to scale reliably and maintain trust. | * How do you ensure these prompts and interfaces are reusable? * Can you track changes for auditability? * How do you log their usage to troubleshoot issues? |
| Evaluate model outputs over time | User feedback loops are essential to monitor performance, but collecting, storing, and acting on feedback systematically is lacking. | * How do you store feedback? * How do you detect dips in accuracy or relevance? * Can you trace poor results back to specific data gaps? |
| Access to multiple data sources for the LLM | GenAI creates data leakage risks (e.g. prompt injection), requiring access controls to secure model interactions. | * Which guardrails or role-based controls prevent unauthorized data exposure? * How do you ensure malicious prompts don’t compromise the agent? |

Transform potential into performance with GenAI
Whether you win or lose in your market may soon rely on having the best GenAI capability and the data foundations to support it. We can help you build this.
Discuss your needsLook beyond your first pilot: apply data product thinking -from day one
A common mistake is solving data challenges only within the narrow context of the initial pilot—resulting in quick fixes that don’t scale. As you tackle more GenAI projects, inconsistencies in data structures, metadata, or security can quickly undermine progress. Instead, adopt a reusable data strategy from day one—one that aligns with your broader data management framework.
Treat core assets like vector databases, knowledge graphs, relational metadata, and prompt libraries as data products. That means assigning ownership, defining quality standards, providing documentation, and identifying clear consumers—so each GenAI use case builds on a solid, scalable foundation.
Core data product ingredients for GenAI
Below, we outline the key principles for making that happen, along with examples, roles, and how to handle incremental growth.
1. Discoverability
Implement a comprehensive data catalogue that documents what data exists, how it's structured, who owns it, and when it's updated. This catalogue should work in conjunction with—but not necessarily be derived from—any knowledge graphs built for specific GenAI use cases. While knowledge graphs excel at modelling domain-specific relationships, your data catalogue needs broader enterprise-wide coverage. Include the metadata and examples needed for generating SQL queries, as well as references for your vector database. (This is something we find particularly useful, for example when developing AI agents that autonomously generate SQL queries to search through databases. Curated, detailed metadata, including table schemas, column definitions, and relationships allow the agents to understand the structure and semantics of the databases.) Define a scheduled process to keep these inventories current, to ensure that new GenAI projects can easily discover existing datasets or embeddings, while avoiding unnecessary re-parsing or re-embedding of data that is already available.
2. Quality standards
This includes a range of processes. From reviewing PDF documents to remove or clarify checkboxes and handwritten text to checking chunk-level completeness for embeddings, consistent naming conventions, or standardized templates for prompt outputs. Involve domain experts to clarify which fields or checks are critical, and align those standards in your data catalogue. By enforcing requirements at the source, you prevent silent inconsistencies (like missing metadata or mismatched chunk sizes) from undermining your GenAI solutions later on.
3. Accessibility
GenAI models require consistent, reliable ways to retrieve information across your enterprise landscape—yet building a custom integration for every data source quickly becomes unsustainable. As an example, at a client a separate data repository was created—with its own API and security—to pull data from siloed systems. This is where the MCP comes in handy: by specifying a standard interface for models to access external data and tools, it removes much of the overhead associated with custom connectors. Not all vendors support MCP but adoption is growing (OpenAI for example provides it). So keep that in mind and avoid rushing into building custom connectors for every system. In sum, focus on building a solid RAG foundation for your most critical, large-scale enterprise data—where the return on investment is clear. For simpler or lower-priority use cases, it may be better to wait for MCP-ready solutions with built-in search, rather than rushing into one-off integrations. This balanced approach lets you meet immediate needs while staying flexible as MCP adoption expands. (We’ll dive deeper into MCP in our next blog post.)
4. Auditability
Log every step—when doing at least make sure to include knowledge graph updates to prompts, reasoning, and final outputs—so you can pinpoint which data, transformations, or model versions led to a given response. This is especially vital in GenAI, where subtle drifts (like outdated embeddings or older prompt templates) often go unnoticed until user trust is already compromised. From a compliance perspective, this is critical when GenAI outputs influence business decisions. Organizations may need to demonstrate exactly which responses were generated, what processing logic was applied, and which data was used at specific points in time—particularly in regulated industries or during audits. Ensure each logged event links back to a clear version ID for both models and data, and store these audit trails securely with appropriate retention policies to meet regulatory, privacy, and governance requirements.
5. Security & access control
Ensure appropriate role- and attribute-based access is enforced on all data sources accessed by your model, rather than granting blanket privileges. Align access with the end-user's identity and context, preventing the model from inadvertently returning unauthorized information. Be particularly vigilant about prompt injection attacks—where carefully crafted inputs manipulate models into bypassing security controls or revealing sensitive information. This remains one of GenAI's most challenging security vulnerabilities, as traditional safeguards can be circumvented through indirect methods. Consider implementing real-time checks, especially in autonomous agent scenarios, alongside an "LLM-as-a-judge" layer that intercepts and sanitizes prompts that exceed a user's permissions or exhibit malicious patterns. While no solution offers perfect protection against these threats, understanding the risk vectors and implementing defence-in-depth strategies significantly reduces your exposure. Resources like academic papers and technical analyses on prompt injection techniques can help your team stay informed about this evolving threat landscape.
6. LLMOps
A shared, organization-wide LLMOps pipeline and toolkit gives every GenAI project a stable, reusable foundation—covering everything from LLM vendor switching and re-embedding to common connectors and tool interfaces. Centralizing these resources eliminates ad-hoc solutions, promotes collaboration, and ensures proper lifecycle management. The result: teams can launch GenAI initiatives faster, apply consistent best practices, and still stay flexible enough to experiment with different models and toolchains.
The takeaway: combine your GenAI implementation with proper data management
Implementing GenAI models and agentic systems isn’t just about prompting an LLM. It’s a data challenge and an architectural exercise. By starting with a high-impact use case, you secure immediate value and insights, while robust data management practices ensure you stay in control—maintaining quality and trust as AI spreads across your organization. By adopting these principles in your very first GenAI initiative, you avoid the trap of quick-win pilots that ultimately buckle under growing data complexity. Instead, each new use case taps into a cohesive, well-governed ecosystem—keeping your AI agents current, consistent, and secure as you scale.
Those who excel at both GenAI innovation and data management will be the ones to transform scattered, siloed information into a unified, GenAI-ready asset—yielding genuine enterprise value on a foundation built to last. If you haven’t already established data management standards and principles, don’t wait any longer—take a look at our blog posts on data management fundamentals part 1 and 2.
If you’d like to learn more about building a robust GenAI foundation, feel free to reach out to us.
This article was written by Daan Manneke, Data & AI Engineer at Rewire and Frejanne Ruoff, Principal at Rewire.
Managing change across interconnected data products is hard. A robust versioning strategy is key avoiding chaos and build a resilient, innovation-ready data ecosystem.
Many organizations are shifting towards federated data management setups in which data management is largely decentralized, enabling domains to develop their own data products. It’s an attractive model for large enterprises, promising reduced bottlenecks from central teams, faster innovation, and domain-specific decision-making.
In short: scalable data management!
However, decentralization introduces complexity, both technical and organizational. Take data interoperability as an example: as each domain builds and manages its own data products, integrating data across domains becomes increasingly complex. Different data models, formats, schemas and definitions make it hard to ensure easy data integration.
Other areas of concern include data security, discoverability and quality. As data products become more interconnected – where one product’s output feeds into another, especially across domains – another significant challenge emerges: managing changes made to these products. Without a well-coordinated versioning strategy, this can quickly lead to cascading disruptions in the data ecosystem.
In this blog post, we’ll explore why a versioning strategy is critical, why it is particularly complex in federated set-ups, and what makes a good data versioning strategy.
In a mesh of interconnected data products, a coordinated versioning strategy is critical
In a typical mesh of data products, these products don’t operate in isolation. They are usually interdependent, where one product’s input is another product’s output. This creates a complex web of relationships. When a change is made to one data product—whether it is an update, bugfix, or new feature release—it affects all downstream products (see below figure).
Figure 1: Potential consequences if one data product changes in a mesh of connected data products
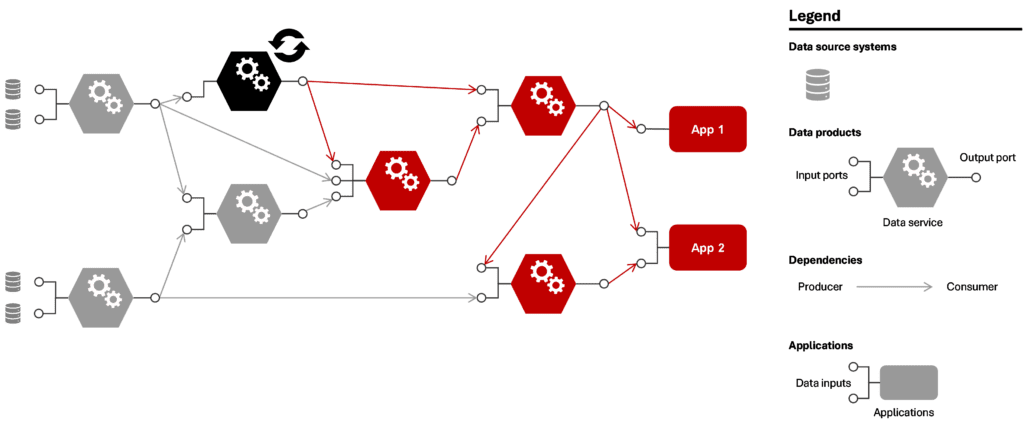
Even when changes happen infrequently, the interconnected nature of the system can cause the impact to snowball quickly. This is referred to as a cascading failure: a single change can spread through the system and cause unexpected behavior in products far removed from the original change. This makes it crucial to carefully manage dependencies and changes to maintain system stability.
Long-term consequence: loss of trust
Because relatively small changes can have such big impacts and lead to an unstable mesh, it can eventually erode trust in the entire system of data products. Over time, this lack of trust may push teams to revert to outdated methods like point-to-point connections or duplicating upstream data products, undermining the benefits of a decoupled (federated) approach.
What drives complexity in data product versioning in a federated set-up
Three aspects of data product versioning render the task complex. Let’s review them turn by turn.
1. Versioning is a significant technical challenge that goes beyond tracking data changes
Versioning presents a significant technical challenge. It’s not just about tracking changes in the data itself. It also involves managing the versioning of data transformation code, deployment code, access control policies, required packages, and supporting infrastructure. Extensive rollback capabilities are needed so that when something goes wrong, everything can be quickly and easily reverted back to a stable state.
How can we keep this mesh of interconnected data products healthy and stable while still allowing teams to innovate and release new updates?
2. More teams managing versions means greater complexity
In a federated set-up, data product versioning is no longer handled by a central team but by each domain independently. As a result, it becomes crucial to establish clear processes for version management across the organization. Without centralized oversight, coordinating large upgrades and ensuring alignment between domains can easily become unmanageable.
3. Innovation and business continuity are often at odds
Lastly, it can be difficult to balance innovation and stability. While decentralized approaches are often introduced to foster innovation and give teams greater freedom to ship new versions and iterate quickly, they must also ensure that changes don’t disrupt downstream consumers—or, in the worst case, compromise business continuity. This challenge grows as domains and interconnected data products proliferate.
Client example: In one organization, data products were initially built and maintained by a central data team. While this ensured stability, it also created long lead times and bottlenecks for new data needs. To speed up delivery, domain teams were allowed to develop their own data products. This worked well at first, but as teams began to use each other's outputs, this system quickly broke down: changes like renaming a column or modifying a metric caused dashboards to fail and models to crash, often without warning. With no shared versioning strategy in place, teams unintentionally disrupted each other almost weekly. The lack of transparency and coordination made the system nearly unmanageable. This example is not unique: it is typical of many organizations transitioning to a federated data model.
What makes a good data versioning strategy?
Given these complexities, organizations need to adopt a coordinated approach to data product versioning. Here we discuss three key components of a successful versioning strategy. Let’s review them one by one.
1. Unified versioning standards across domains
To avoid fragmentation and promote cross-domain data consumption, teams should follow consistent versioning guidelines that ensure clarity and interoperability across domains. These guidelines could include:
- Semantic versioning . This is a best practice versioning system adopted from software engineering, which distinguishes between major, minor, and patch updates. This approach data products updates to be labelled depending on the magnitude of the change and expected impact for consumers. As an example, semantic versioning for data products could look like the following:
- Patches involve bug fixes and performance optimizations.
- Minor updates introduce new capabilities, non-breaking to consumers, such as added columns and additional observability elements.
- Major updates are likely breaking to consumers, such as data type changes and definition changes.
- Unified communication mechanisms to notify stakeholders of upcoming changes, preferably automated when breaking changes are coming up.
- Clear documentation of changes, including expected impact on dependent data products, following the semantic versioning format and captured in changelogs.
The level of standardization should match the organization's complexity - too rigid frameworks can unnecessarily hinder innovation in smaller teams, while too loose approaches can lead to chaos in organizations with many domains.
2. Clear management of dependencies
In highly interconnected data ecosystems, dependency management must be explicit and transparent to prevent downstream failures. By giving downstream consumers visibility and time to adapt, organizations can prevent cascading failures and system instability. Key measures include:
- Transparency in data lineage. That is, ensuring that teams know where their data originates from, and which consumers depend on their data products.
- Structured rollout strategies such as parallel releases. This allows new and old versions to coexist for a transition period (a.k.a. the grace period) during which consumers have time to adapt before the old version is deprecated.
Client example: At a large financial institution, domain teams were unaware of the consumers of their data assets, or the use cases downstream of their data products. This resulted in slightly different versions of the same data being used throughout the organization. By adopting an approach that provided company-wide visibility into data lineage, and automatically updating it based on changes in data production and consumption, the client was able to untangle the ‘data spaghetti’ that had emerged from a lack of oversight.
3. Automation and tooling
Automated versioning is near-essential to make maintenance of data products efficient at scale, and error-free. Automation reduces human error, accelerates version rollouts, and ensures that versioning remains consistent and manageable even as the number of data products grows. Key elements include:
- Rollback capabilities to revert to stable versions when issues arise.
- Automated validation and testing to detect compatibility issues before deployment.
- Versioning as code, where versioning rules and policies are embedded in infrastructure and deployment pipelines.
- Developer tools that integrate with CI/CD pipelines, making versioning seamless for data engineers.
Client example: At one of our clients, we made the changelog an integral component in the lifecycle of data products. Through this approach, data products could not be altered without updating the changelog, making the changelog the source of truth for deployments and data product evolution. The CI/CD process for testing and deploying data products included analysis of the changelog, extracting the changes of the document, testing if these were following the intended versioning strategy (e.g. not skipping versions, checking if the documents includes information on the changes, analyzing whether it involves breaking changes), and if successful: deploying the data product, by changing the infrastructure and transformation logic according to the pre-defined deployment strategy. This approach improved the governance of data products in the organization and made it easier for data product builders to roll out changes.
Conclusion
For organizations adopting federated data management, the way they approach data product versioning can be the deciding factor in the success or failure of their data mesh. A strong versioning strategy is more than just a technical necessity - it is the foundation for maintaining a stable yet flexible data ecosystem. The key is to strike the right balance: ensuring interoperability between domains, without hindering innovation. By setting clear standards, proactively managing data dependencies, and using automation, organizations can ensure that their federated data products evolve seamlessly - allowing teams to innovate while keeping the ecosystem resilient and reliable.
This article was written by Job van Zijl, Senior Data Engineer at Rewire and Tamara Kloek, Principal at Rewire.
From interoperability to generative data management, here are the key trends shaping the data management agenda
Curious about what 2025 holds for Data Management? This article offers a strategic perspective on the trends that we expect will demand the most attention.
But first things first: let’s look at where we are today.
It is widely recognized that Data Management is the main bottleneck when scaling AI solutions. More and more companies see the benefits of good data management when building scalable data & AI capabilities. In fact, to do anything meaningful with data, your business must organize for it.
However, there is no one-size-fits-all data management strategy. How to organize depends on what you want to accomplish and what your business considers critical. Regardless of whether your organization adopted defensive or offensive data strategies, 2024 was marked by the fact that nearly all companies were addressing these three challenges:
- Balancing centralization versus decentralization. Data mesh principles bring data federation into focus. That is, strategically determining the level of domain autonomy versus standardization in order to balance agility with consistency.
- Explicitly linking data management with use case value. Many companies have started properly building a business case for data. Both value and costs have become part of the equation, as part of a shift from big data to high quality data.
- Managing the trade-off between flexibility, scalability and technical debt. This involves deciding between highly automated, low-code platforms for users of varying technical skills vs. high-code frameworks for experienced developers who work on tailored solutions.
Moving on to 2025, we expect the key trends to be:
- Interoperability –to overcome heterogeneous technologies and data semantics across organizational siloes.
- Generative data management –to enable both GenAI use cases from the information contained in the data, as well as GenAI data governance agents.
- Balancing data democratization with people capabilities –to foster high quality decision-making. This involves both high data trustworthiness and building people's ability to work with the data.
Now let's review them one by one.
Trend #1. Interoperability
Building scalable data management typically evolves to a stage where decentralized domain teams take ownership, and data definitions and discoverability are effectively addressed. However, this creates a landscape with both heterogeneous technology and data across domains. For companies that have adopted offensive data strategies, this means that domain-transcending use cases are hampered as the underlying data cannot be integrated. For companies that have adopted defensive data strategies, this means that meeting the regulatory requirements (e.g. CSRD) that require company-wide integrations, are at risk. Either way, the promise of interoperability is to reap the value for cross-domain use cases.
When designing interoperability solutions, we need to start by asking what data should be common across domains and how to handle the heterogeneity over domains to deliver the value in cross-domain use cases. Here the challenge from heterogeneous data can be expected to be more complex than the challenge that stems from heterogeneous technology.
What about implementation? While property graphs, ontologies, query federation engines and semantic mapping technologies are serious contenders for providing a strong technological basis for interoperability, scaling these solutions remain unproven. However, we anticipate that 2025 will be a breakthrough year, with leading companies in data management demonstrating successful large-scale implementations—potentially integrating access management solutions as an additional layer atop the interoperability framework.
The journey doesn’t stop there: achieving end-to-end interoperability hinges on the collaboration of your people. Addressing use cases with cross-domain questions demands a coalition of domain experts working together to craft semantic models and establish a shared language, essential for breaking down silos and fostering seamless integration.
Trend #2. Generative data management
Whereas the general public enthusiastically adopted GenAI in 2024, we expect 2025 to be marked by the integration of GenAI into business processes. However, successfully embedding this new class of data solutions will depend heavily on effective data management.
Drawing parallels with predictive AI, it’s clear that integrating GenAI into business operations requires robust data management frameworks. Without this foundation, businesses risk a proliferation of siloed point solutions, which later require costly redevelopment to scale. Moreover, the risks associated with the classic "garbage in, garbage out" rule are even more pronounced with GenAI, making high-quality data a critical prerequisite. In short: fix your data first.
Interestingly, GenAI itself can play a pivotal role in addressing data management challenges. For instance, GenAI-powered data governance stewards or agents can automate tasks like metadata creation and tracking data provenance. (Check out our article on Knowledge Graphs and RAG to learn more about their transformational powers.)
For companies with offensive data strategies, thriving with GenAI requires aligning its deployment with a solid data management strategy. Meanwhile, defensive strategies can leverage GenAI to automate tasks such as data classification, metadata generation, and tracking data lineage across systems.
To make all this work, companies must solve the challenges of technological interoperability, allowing GenAI use cases to access and benefit from diverse datasets across platforms. Since GenAI relies on a variety of labeled data to perform optimally, addressing these challenges is critical.
All in all, we believe 2025 will be the year GenAI begins transforming data management for businesses that recognize it requires a fundamentally different approach than predictive AI. The companies that adapt will lead the way in this next wave of innovation.
Trend #3. Balancing democratization of data with people capabilities
Many companies began their data transformation journeys on a small scale, often driven by technology. This has now led to broader data availability within organizations, bringing both opportunities and challenges. Two key outcomes are emerging:
First, to empower the right people, it's important to evaluate where you are today, and what responsibilities and competencies you require from the people within your organization. This feeds back into the level of abstraction of technical capabilities, the training curriculum and the purpose of your accelerator teams. For more details check out this blog post on data management adoption.
Second, trustworthiness and quality of the data becomes more critical than ever. Indeed, low quality data and lack of trust in the data can cause significant organizational noise and costs. (Consider the impact of erroneous sales data accessed by 100 users and systems, with all reports and decisions based on it propagating those inaccuracies).
For companies with offensive data strategies, high-quality data products enable scalability, allowing less technical domain experts to contribute more effectively to building solutions. For defensive strategies, robust trust and quality checks pave the way for "data management by design," enabling a shift from "human in the loop" to "human on the loop".
In sum, we believe 2025 will mark a turning point in data management, characterized by higher levels of automation and an improved developer experience. This will make data management more accessible to a wider range of people while requiring a step up in both people skills and data quality. Striking the right balance between these elements will be critical for success.
The road ahead
The market around data & AI is rapidly changing. It is also filled with noise, from the latest data management tools to emerging paradigms (e.g. data mesh, grid, fabric, and so on). Without a focused approach, it’s easy to lose sight of what truly matters for your organization.
Addressing this challenge is much like conducting an orchestra, where people, technology, and organizational elements must work in harmony on a transformational journey. Missteps can lead to isolated point solutions or inadvertently create a new bottleneck. But with the right mix of experience, skill, and knowledge, success is absolutely achievable. In an earlier blogpost we shared our perspective on making data management actionable. Are you ready to step into the role of the conductor, orchestrating data management for your organization? If so, contact us to share your experience!
This article was written by Nanne van't Klooster, Program Manager, Freek Gulden, Lead Data Engineer, and Frejanne Ruoff, Principal at Rewire.
It takes a few principles to turn data into a valuable, trustworthy, and scalable asset.
Imagine a runner, Amelia, who finishes her run every morning eager to pick up a nutritious drink from her favorite smoothie bar, "Running Smoothie”, at the corner of the street. But there’s a problem: Running Smoothie has no menu, no information about ingredients or allergens, and no standards for cleanliness or freshness. Even worse, some drinks should be restricted based on age — like a post-run mimosa — but there is no way to identify the drinks for adults only. For long time customers like Amelia, who know all products by heart, this isn’t much of an issue. But new customers, like Bessie, find the experience confusing and unpleasant, often deciding not to return.
Sounds strange, right? Yet, this is exactly how many organizations treat their data.
This scenario parallels the typical struggles organizations face in data management. Data pipelines can successfully transfer information from one system to another, but this alone doesn’t make the data findable, usable, or reliable for decision-making. Take a Sales team processing orders, for instance. That same data could be highly valuable for Finance, but it won’t deliver any value if the Finance team isn’t even aware the pipeline exists. This highlights a broader issue: simply moving data from point A to B falls short of a successful data exchange strategy.
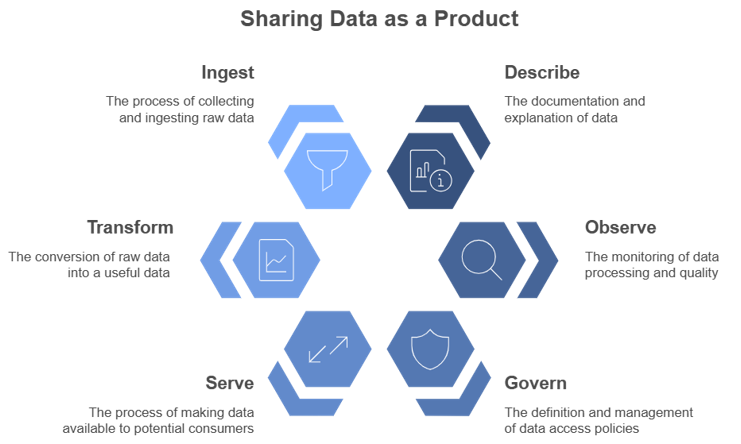
Effectively sharing Data as a Product requires sharing described, observable and governed data to ensure a smooth and scalable data exchange.
In response to this, leading organizations are embracing data as a product — a shift in mindset from viewing data as an output, to treating data as a strategic asset for value creation. Transforming data into a strategic asset requires attention to three core principles:
- Describe: ensure users can quickly find and understand the data they need, just as a well-labeled menu listing ingredients and allergens helps Bessie know what she can order.
- Observe: share data quality and reliability over time, both expected standards and unexpected deviations — like information on produce freshness and flagging when customers must wait longer than usual for their drink.
- Govern: manage who can access specific data so only authorized individuals can interact with sensitive information, similar to restricting alcoholic menu items based on an age threshold.
By embedding these foundational principles, data is not just accessible but is transformed into a dependable asset to create value organization-wide. This involves carefully designing data products with transparency and usability in mind, much like one would expect from a reputable restaurant's menu.
In this blog, we will explore why each principle is essential for an effective data exchange.
Describe: ensure data is discoverable and well-described
For data to create value, consumers need to be able to find, understand, and use it. If your team produces a dataset that’s crucial to multiple departments but remains tucked away on a platform no one knows about or is not well described and remains ambiguous, your crucial dataset might as well be invisible to potential consumers.
Findable data requires a systematic approach to metadata: think of it as the digital “menu listing” of data that helps others locate and understand it. Key metadata elements include the data schema, ownership details, data models, and business definitions. By embedding these in, for example, a data catalog, data producers help their consumers not only discover data but also interpret it accurately for their specific needs.
Observe: monitor data quality and performance
The next step is to share data quality—consumers need to know that what they are accessing is reliable. Data lacking quality standards leave users guessing whether the data is recent, consistent, and complete. Without transparency, consumers might hesitate to rely on data or worse, make flawed decisions based on outdated or erroneous information.
By defining and sharing clear standards around data quality and availability —such as timeliness, completeness, and accuracy— you enable consumers to determine if the data meets their needs. Providing observability into performance metrics, such as publishing data update frequency or tracking issues over time, allows users to trust the data and promotes data quality accountability.
Govern: manage data access and security
Finally, a successful data product strategy is built on well-managed data access. While data should ideally be accessible to any team or individual who can create value from it, data sensitivity and compliance requirements must be taken into account. Yet, locking all data behind rigid policies slows down collaboration and might lead teams to take risky shortcuts.
A well-considered access policy strikes the right balance between accessibility and security. This involves categorizing data access levels based on potential use cases, and establishing clear guidelines on who can view, modify, or distribute data. Effectively managed access not only safeguards sensitive information but also builds trust among data producers, who can rest assured their data is treated confidentially. Meanwhile, consumers can access and use data confidently, without friction or fear of misuse.
Sounds easy, but the devil is in the details
For many, these foundational principles may seem straightforward. Yet, we often see companies fall into the trap of relying solely on technology to solve their Data & AI challenges, neglecting to apply these principles holistically. This tech-first approach often results in poor adoption and missed opportunities due to a lack of focus on organizational context and value delivery.
Take data catalogs, for example — essential tools for data discoverability. While it may seem like a simple matter of choosing the right tool, driving real change requires a comprehensive approach that incorporates best practices from the Playbook to Scalable Data Management. Without them, companies face long-term risks where:
- Due to a lack of standards the catalog features data duplication, inconsistent definitions, no clear or recursively looping data lineage, and so on. For consumers of the data, this makes it difficult to navigate eroding its usefulness.
- Due to a lack of requirements the catalog is helpful for some teams, but useless for others, inviting proliferation of alternative tools further complicating data access and reducing overall adoption.
This illustrates the fact that something as fundamental as a data catalog isn’t just a technological fix. Instead, it requires a coordinated, cross-functional effort that aligns with business priorities and data strategy: it is not about implementing the right tool, but about implementing the tool the right way.
Conclusion: Data as a Product, not just Data
In the end, successfully sharing data across an organization is about more than just setting up access points and handing over datasets. It demands a holistic approach to data discoverability, observability, and governance suited to your organization. By embedding these principles, organizations can overcome common pitfalls in data sharing and set up a robust foundation that turns data into a true organizational asset. It’s not only a strategic shift in data management but also a cultural one that lays the foundation for scalable, data-driven growth.
This article was written by Femke van Engen, Data Scientist, Simon Beets, Data & AI engineer, and Freek Gulden, Lead Data Engineer at Rewire.
Jonathan Dijkslag on growing and maintaining the company's edge in biotechnology and life sciences
In the latest episode of our podcast, Jonathan Dijkslag, Global Manager of Data Insights & Data Innovation at Enza Zaden, one of the world’s leading vegetable breeding companies sits down with Ties Carbo, Principal at Rewire. With over 2,000 employees and operations in 30 countries, Enza Zaden has built its success on innovation, from pioneering biotechnology in the 1980s to embracing the transformative power of Data & AI today.
Jonathan shares insights into the company’s data-driven journey, the challenges of integrating traditional expertise with modern technology, and how cultivating a culture of trust, speed, and adaptability is shaping Enza Zaden’s future. Tune in to discover how this Dutch leader is using data to revolutionize vegetable breeding and stay ahead in a competitive, innovation-driven industry.
Watch the full interview
The transcript below has been edited for clarity and length.
Ties Carbo: Thank you very much for joining this interview. Can you please introduce yourself?
Jonathan Dijkslag: I work at Enza Zaden as the global manager of Data Insights and Innovation. My mission is to make Enza Zaden the most powerful vegetable-breeding company using data.
"It's about how to bring new skills, new knowledge to people, and combine it all together to deliver real impact."
Jonathan Dijkslag
Ties Carbo: Can you tell us a little bit about your experience on working with Data & AI?
Jonathan Dijkslag: What made Enza very successful is its breeding expertise. We are working in a product-driven market and we are really good at it. Enza grew over time thanks to the expertise of our people. In the 80s, biotech came with it. And I think we were quite successful in adapting to new technologies.
Now we are running into an era where data is crucial. So I think that data is at the heart of our journey. We are a company that values our expertise. But also we are really aware of the fact that expertise comes with knowledge, and with having the right people able to leverage that knowledge in such a way that you make impact. And that's also how we look at this journey. So it's about how to bring new skills, new knowledge to people, and combine it all together to deliver real impact.
Ties Carbo: It sounds like you're in a new step of a broader journey that started decades ago. And now, of course, Data & AI is a bit more prevalent. Can you tell us a little bit more about some successes that you're having on the Data & AI front?
Jonathan Dijkslag: There are so many, but I think the biggest success of Enza is that with everything we do, we are a conscious of our choices. Over the past three to five years, we have spent quite some money on the foundation for success. So where some companies are quite stressed out because of legacy systems, we do very well in starting up the right initiatives to create solid foundations and then take the time to finalize them. And I think that is very powerful within Enza. So over the past years we have built new skills based on scalable platforms in such a way that we can bring real concrete value in almost all fields of expertise in the company.
Ties Carbo: Can you maybe give a few examples of some challenges you encountered along the way?
Jonathan Dijkslag: I think the biggest challenge is that the devil is in the details. That's not only from a data journey perspective, but also in our [functional] expertise. So the real success of Enza with data depends on really high, mature [functional] expertise combined with very high, mature expertise in data. And bridging functional experts with data experts is the biggest challenge. It has always been the biggest challenge. But for a company like Enza, it's particularly complex.
Another complexity is we have quite some people who for decades have used data heavily in their daily work. Yet the way we use data nowadays is different than compared to decades ago. So the challenge is how to value the contributions made today and at the same time challenge people to take the next step with all the opportunities we see nowadays.
"We learned the hard way that if you don't understand – or don't want to understand what our purpose is as a company, then you will probably not be successful."
Jonathan Dijkslag
Ties Carbo: I was a bit intrigued by your first response – bridging the functional expertise with the Data & AI expertise. What's your secret to doing that?
Jonathan Dijkslag: I think it really comes back to understanding the culture of your company. When I joined the company, I knew that it would take time to understand how things work today. I needed to show my respect to everything that has brought so much success to the company in order to add something to the formula.
Every company has a different culture. Within Enza, the culture is pretty much about being Dutch. Being very direct, clear, result-driven, don't complain. Just show that you have something to add. And that's what we try to do. And learn, learn and adapt. For instance, in the war on talent, we made some mistakes. We thought maybe business expertise is not always that important. But we learned the hard way that if you don't understand – or don't want to understand what our purpose is as a company, then you will probably not be successful. And that means something to the pace and the people you can attract to the company. So it’s all about understanding the existing culture, and acting on it. And sometimes that means that you need more time than you’d like to have the right people or have the right projects finalized and create the impact you want.
"We have to create a mechanism whereby we're not too busy. We have to create a change model where you can again and again adapt to new opportunities."
Jonathan Dijkslag
Ties Carbo: What advice would you give to other companies that embark on a journey like this?
Jonathan Dijkslag: This is the new normal. The complexity is the new normal. So we have to think about how we can bring every day, every week, every month, every year more and more change. And people tend to say “I'm busy, we’re busy, wait, we have to prioritize.” I think we have to rethink that model. We have to create a mechanism whereby we're not too busy. We have to create a change model where you can again and again adapt to new opportunities. And I think this is all about creating great examples. So sometimes it’s better to make fast decisions that afterwards you would rate with a seven or an eight, but you did it fast. You were very clear and you made sure that the teams work with this decision that’s rated seven, rather than thinking for a long period about the best business case or the best ROI. So I think the speed of decision-making close to the area impact. I think that that's the secret.
People talk a lot about agility. I think for me, the most important part of agility is the autonomy to operate. Combined with very focused teams and super fast decision-making and the obligation to show what you did.
Ties Carbo: How is it to work with Rewire?
Jonathan Dijkslag: For me, it's very important to work with people who are committed. I have a high level of responsibility. I like to have some autonomy as well. And to balance those things, I think it's very important to be result-driven and also to show commitment in everything you do. And what we try to do in our collaboration with Rewire is to create a commitment to results. Not only on paper, but instead both parties taking ownership of success. And we measure it concretely. That's the magic. We're really in it together and there's equality in the partnership. That's how it feels for me. So I think that that's the difference.
We work a lot with genetic data. So our challenges are very specific. Life science brings some complexity with it. And we were looking for a partner who can to help us develop the maturity to understand and work with confidence with the corresponding data. And thanks to their experience in the field of life science, they showed that they understand this as well. And that's very important because trust is not easily created. And if you show that you brought some successes in the world of life science - including genetic data - that helps to get the trust, and step into realistic cases.
Ties Carbo: Thank you.
About the authors
Jonathan Dijkslag is the Global Manager of Data Insights & Data Innovation at Enza Zaden, where he drives impactful data strategies and innovation in one of the world's leading vegetable breeding companies. With over 15 years of experience spanning data-driven transformation, business insights, and organizational change, Jon has held leadership roles at Pon Automotive, where he spearheaded transitions to data-driven decision-making and centralized business analytics functions. Passionate about aligning technology, culture, and strategic goals, Jon is dedicated to creating tangible business impact through data.
Ties Carbo is Principal at Rewire.
Allard de Boer on scaling data literacy, overcoming challenges, and building strong partnerships at Adevinta - owner of Marktplaats, Leboncoin, Infojobs and more.
In this podcast, Allard de Boer, Director of Analytics at Adevinta (a leading online classifieds which includes brands like Marktplaats, Leboncoin, mobile.de, and many more) sits down with Rewire Partner Arje Sanders to explore how the company transformed its decision-making process from intuition-based to data-driven. Allard shares insights on the challenges of scaling data and analytics across Adevinta’s diverse portfolio of brands.
Watch the full interview
The transcript below has been edited for clarity and length.
Arje Sanders: Can you please introduce yourself and tell us something about your role?
Allard de Boer: I am the director of analytics at Adevinta. Adevinta is a holding company that owns multiple classifieds brands like Marktplaats in the Netherlands, Mobile.de in Germany, Leboncoin in France, etc. My role is to scale the data and analytics across the different portfolio businesses.
Arje Sanders: How did you first hear about Rewire?
Allard de Boer: I got introduced to Rewire [then called MIcompany] six, seven years ago. We started working on the Analytics academy for Marktplaats and have worked together since.
We were talking about things like statistical significance, but actually only a few people knew what that actually meant. So we saw that there are limits to our capabilities within the organization.
Allard de Boer
Arje Sanders: Can you tell me a little about the challenges that you were facing and wanted to resolve in that collaboration? What were your team challenges?
Allard de Boer: Marktplaats is a technology company. We have enormous technology, we have a lot of data. Every solution that employees want to create has a foundation in technology. We had a lot of questions around data and analytics and every time people threw more technology at it. That ran into limitations because the people operating the technology were scarce. So we needed to scale in a different way.
What we needed to do is get more people involved in our data and analytics efforts and make sure that it was a foundational capability throughout the organization. This is when we started thinking about how to scale specific use cases further. See how we can take what we have, but then make it common throughout the whole organization and then scale specific use cases further.
For example, one problem is that we did a lot of A/B testing and experimentation. Any new feature on Marktplaats was tested through A/B testing. It was evaluated on how it performed on customer journeys, and how it performed on company revenue. This was so successful that we wanted to do more experiments. But then we ran into the limitations of how many people can look at the experimentation, and how many people understand what they're actually looking at.
We were talking about things like statistical significance, but actually only a few people knew what that actually meant. So we saw that there are limits to our capabilities within the organization. This is where we started looking for a partner that can help us to scale employee education to raise the level of literacy within our organization. That's how we came up with Rewire.
We were an organization where a lot of gut feeling decision-making was done. We then shifted to data-driven decision-making and instantly saw acceleration in our performance.
Allard de Boer
Arje Sanders: That sounds quite complex because I assume you're talking about different groups of people with different capability levels, but also over different countries. How did you approach the challenge?
Allard de Boer: Growth came very naturally to us because we had a very good model. Marktplaats was growing very quickly in the Netherlands. Then after a while, growth started to flatten out a bit. We needed to rethink how we run the organization. We moved towards customer journeys and understanding customer needs.
Understanding those needs is difficult because we're a virtual company. Seeing what customers do, understanding what they need is something we need to track digitally. This is why the data and analytics is so vital for us as a company. If you have a physical store, you can see how people move around. If your store is only online, the data and analytics is your only corridor to understanding what the customer needs are.
When we did this change at Marktplaats, people understood instantly that the data should be leading when we make decisions. We were an organization where a lot of gut feeling decision-making was done. We then shifted to data-driven decision-making and instantly saw acceleration in our performance.
Arje Sanders: I like that move from gut feeling-based decision-making to data-driven decision-making. Can you think of a moment when you thought that this is really a decision made based on data, and it's really different than what was done before?
Allard de Boer: One of the concepts we introduced was holistic testing. Any problem we solve on Marktplaats is like a Rubik's Cube. You solve one side, but then all the other sides get messed up. For example we introduced a new advertising position on our platform, and it performed really well on revenue. However, the customers really hated it. When only looking at revenue, we thought this is going well. However, if you looked at how customers liked it, you saw that over time the uptake would diminish because customer satisfaction would go down. This is an example of where we looked at performance from all angles and were able to scale this further.
After training people to know where to find the data, what the KPIs mean, how to use them, what are good practices, what are bad practices, the consumption of the data really went up, and so did the quality of the decisions.
Allard de Boer
Creating a blueprint for AI Transformation
Our strategies elevate the performance of your AI applications from marginal or tactical results to unequivocal, transformational successes.
Discuss your needsArje Sanders: You mentioned that in this entire transformation to become more data-driven, you needed to do something about people's capabilities. How did you approach that?
Allard de Boer: We had great sponsorship from the top. We had a visionary leader in the leadership team. Because data is so important to us as a company, everybody from the receptionist to the CEO, needs to have at least a profound understanding of the data. Within specific areas, of course, we want to go deeper and much more specific. But everybody needs to have access to the data, understand what they're looking at, and understand how to interpret the data.
Because we have so many data points and so many KPIs, you could always find a KPI that would go up. If you only focus on that one but not look at the other KPIs, you would not have the full view of what is actually happening. After training people to know where to find the data, what the KPIs mean, how to use them, what are good practices, what are bad practices, the consumption of the data really went up, and so did the quality of the decisions.
Arje Sanders: You said that you had support from the top. How important is that component?
Allard de Boer: For me, it’s vital. There's a lot of things you can do bottom up. This is where much of the innovation or the early starting of new ideas happen. However, when the leadership starts leaning in, that’s when things accelerate. Just to give you an example, I was responsible for implementing certain data governance topics a few years back. It took me months to get things on the roadmap, and up to a year to get things solved. Then we shifted the company to focus on impact and everybody had to measure their impact. Leadership started leaning in and I could get things solved within months or even weeks.
Arje Sanders: You've been collaborating with Rewire on the educational program. What do you like most about that collaboration, about this analytics university that we've developed together?
Allard de Boer: There are multiple things that really stand out for me. One is the quality of the people. The Rewire people are the best talent in the market. Also, when developing this in-house analytics academy, I was able to work with the best people within Rewire. It really helped to set up a high-quality program that instantly went well. It's also a company that oozes energy when you come in. When I go into your office, I'm always welcome. The drinks are always available at the end of the week. I think this also shows that it is a company of people working well together.
Arje Sanders: What I like a lot in those partnerships is that it comes from two sides. Not every partnership flourishes, but those that flourish, those are the ones that also open up to a real partnership. Once you have that, then you really see an accelerated collaboration. I like that a lot about that, working together.
Allard de Boer: Yes. Rewire is not just a vendor for us. You guys have been a partner for us from the start. I've always shared this as a collaborative effort. We could have never done this without Rewire. I think this is also why it's such a strong partnership over the many years.
For information about how to build Data & AI capabilities, visit GAIN - Rewire's Data & AI training unit.
About the authors
Allard de Boer is the Director of Global Data & Analytics at Adevinta, where he drives the scaling of data and analytics across a diverse portfolio of leading classifieds brands such as Marktplaats, Mobile.de, and Leboncoin. With over a decade of experience in data strategy, business transformation, and analytics leadership, Allard has held prominent roles, including Global Head of Analytics at eBay Classifieds Group. He is passionate about fostering data literacy, building scalable data solutions, and enabling data-driven decision-making to support business growth and innovation.
Arje Sanders is Partner at Rewire.
From chess-playing robots to a future beyond our control: Prof Stefan Leijnen discusses the challenges of AI and its evolution
Stefan’s Leijnen experience spans cutting-edge AI research and public policy. As professor in applied AI, he focuses on machine learning, generative AI, and the emergence of artificial sentience. As the lead for EU affairs for the Dutch National Growth Fund project AiNed, Stefan plays a pivotal role in defining public policy that promotes innovation while protecting citizens’ rights.
In this captivating presentation, Stefan takes us on a journey through 250 years of artificial intelligence, from a chess-playing robot in 1770 to the modern complexities of machine learning. With thought-provoking anecdotes he draws parallels between the past and the ethical challenges we face today. As the lead in EU AI policy, Stefan unpacks how AI is reshaping industries, from Netflix’s algorithms to self-driving cars, and why we need to prepare for its profound societal impacts.
Below we summarize his insights as a series of lessons and share the full video presentation and its transcript.
Prepare to rethink what you know about AI and its future.
Lesson 1. AI behaviour is underpinned by models that cannot be understood by humans
10 years ago, Netflix asked the following question: “How do we know that the categories that we designed with our limited capacity as humans are the best predictors for your viewing preferences? We categorize people according to those labels, but those might not be the best labels. So let’s reverse engineer things: now that we have all this data, let’s decide what categories are the best predictors for our viewership.” And they did that. And so they come up with 50 dimensions or 50 labels, all generated by the computer, by AI. And 20 of them made a lot of sense: gender, age, etc. But for 30 of those 50 labels, you could not identify the category. That means that the machine uncovered a quality among people that we don’t have a word for. For Netflix this was great because it meant they now had 30 more predictors. But on the other hand, it’s a huge problem. Because now if you want to change something in those labels or you want to change something in the way that you use the model, you no longer understand what you’re dealing with.
Watch the video clip.
Lesson 2. AI’s versatility can lead to hidden – and very hard – ethical problems
Let’s say the camera of a self-driving car spots something and there’s a 99% chance that it is just a leaf blowing by, and a 1% chance that it’s a child crossing the street. Do you break? Of course, you would break in a 1% chance. But now let’s lower the chance to 0.1% or 0.01%. At what point do you decide to break?
The point, of course, is that we never make that decision as humans. But with rule-based programs, you have to make that decision. So it becomes an ethical problem. And these kind of ethical problems are much more difficult to solve than technological problems. Because who’s going to answer that? Who’s going to give you this number? It’s not the programmer. The programmer will go to the manager or to the CEO and they will go to the legal division or to the insurer or to the legislator. And nobody’s willing to provide an answer. For moral reasons (and for insurance reasons), it’s very difficult to solve this problem. Now, of course, nowadays there’s a different approach: just gather the data and calculate the probability of breaking that humans have. But in doing so, you have moved the ethical challenge under the rug. But it’s still there. So don’t get fooled by those strategies.
Watch the video clip.
Lesson 3. AI impact is unpredictable. But its impact won’t be just technological. It will be societal, economical, and likely political
There are other systems technologies like AI. We have the computer, we have the internet, we have the steam engine and electricity. And if you think about the steam engine, when it was first discovered, nobody had a clue of the implications of this technology 10, 20 or 30 years down the line. The first steam engines were used to automate factories. So instead of people working on benches close to each other, the whole workforce was designed along the axis of this steam engine so everything would be mechanically automated. This meant a lot of changes to the workforce. It meant that work could go for hours on end, even in the evenings and in the weekends. That led to a lot of societal changes. So labor forces emerged, you had unions, you had new ideologies popping up. The steam engine also became a lot smaller. You got the steam engine on railways. Railways meant completely different ways of warfare, economy, diplomacy. The world got a lot smaller. This all happened in the time span of several decades. We will see similar effects that are completely unpredictable as AI gets rolled out in the next couple of decades. Most of these effects of the steam engine were not technological. They were societal, economical, sometimes political. So it’s also good to be aware of this when it comes to AI.
Watch the video clip.
Lesson 4. The interfaces with AI will evolve in ways we do not yet anticipate.
The AI that we know now is very primitive. Because what we see today in AI is a very old interface. With ChatGPT, it’s a text command prompt. When the first car was invented, it was a horseless carriage. When the first TV was invented, it was essentially radio programming with an image glued on top of it. Now, for most of you who have been following the news, you already see that the interfaces are developing very rapidly. So you’ll get voice interfaces, you’ll get a lot more personalization with AI. This is a clear trend.
Watch the video clip.
Watch the full video.
(Full transcript below.)
Full transcript.
The transcript has been edited for brevity and clarity.
Prof Leijnen: Does anybody recognize this robot that I have behind me? Not many people. Well, that’s not surprising because it’s a very old robot. This robot was built in the year 1770, so over 250 years ago. And this robot can play chess.
And it was not just any chess-playing robot. It was actually an excellent chess-playing robot. He won most games. And as you can imagine at that time, it was a celebrity. This robot played against Benjamin Franklin. It played against emperors and kings. It also played a game against Napoleon Bonaparte. We know what happened because there were witnesses there. In fact, Napoleon being the smart man that he is, he decided to play a move in chess that’s not allowed just to see the robot’s reaction. What the robot did is it took the piece that Napoleon moved and put it back in its original position.
Napoleon being inventive, did the same illegal move again. Then the robot took the piece and put it beside the board as though it’s no longer in the game. Napoleon tried a third time and then the robot wiped all the pieces off the board and decided that the game was over, to the amusement of the spectators. Then they set up the pieces again, played another game and Napoleon lost. Well, to me, this is really intelligence.
You might think or not think that this is artificial intelligence. If you think this is not artificial, you’re right. Because there’s this little cabinet which has like magnets and strings and there was a very small person that could fit inside this cabinet and who was very good at playing chess. And of course, he is the person who played the game. People only found out about 80 years after the facts when the plans were revealed by the son of von Kempelen.
Now, there was another person who played against this robot and his name was Charles Babbage. And Charles Babbage is the inventor of this machine, the analytical engine. And it’s considered by many to be the first computer in the world. It was able to calculate logarithms. Interestingly, Babbage played against the robot that you just saw. He also lost in 18 turns. But I like to imagine that Babbage must have been thinking how does this robot work, what’s going on inside.
As some of you may know, a computer actually beat the world champion in chess, Gary Kasparov in 1997. So you could say in this story spanning 250 years is a nice story arc. Because now we do have AI that can play and win chess, which was the original point of the chess-playing robots. So we’re done. We’re actually done with AI. We have AI now. The future is here. But at the same time, we’re not done at all. Because now we have this AI and we don’t know how to use it. And we don’t know how to develop it further.
There is a nice example from Netflix, the streaming company. They collect a lot of data. They have your age, gender, postal code, maybe your income. They know things about you. And then based on those categories, they try to predict with machine learning what type of series and movies you like to watch. And this is essentially their business model. Now, 10 years ago they asked the following question: “How do we know that the categories that we designed with our limited capacity as humans are the best predictors for your viewing preferences? We categorize people according to those labels, but those might not be the best labels. So let’s reverse engineer this machine learning algorithm. And now that we have all this data, let’s decide what categories are the best predictors for your viewership.”
And they did that. And they came up with 50 dimensions or 50 labels that you could attach to a viewer, all generated by the computer, by AI. And 20 of them made a lot of sense. So you would see men here, women there. You would see an age distribution. And there was very clear preferences in viewership. Of course, not completely uniform, but you could identify the categories and you could attach a label to them.
Now for 30 of those 50 labels, you could not identify the category. For example, for one of the 30 categories, you would see people on the left side, people on the right side. On the left side, they had a strong preference for the movie “American Beauty.” And on the right side, they had a strong preference for X on the beach. And nobody had any clue what discerned the group on the left from the group on the right. So that means that there was a quality in those groups of people that we don’t have a word for. We don’t know how to understand that. Which for Netflix was great because it means they had now 30 more predictors they could use to do good predictions. But on the other hand, it’s a huge problem. Because now if you want to change something in those labels or you want to change something in the way that you use the model, you no longer understand what you’re dealing with.
And this is essentially the topic of what I am talking about today. How do you manage something you can’t comprehend? Because essentially that’s what AI is. And this is not just a problem for companies implementing AI. We all know plenty of examples of AI going wrong. And when it goes wrong, it tends to go wrong quite deeply. Like in this case, if you ask AI to provide you with an image of a salmon, the AI is not wrong. Statistically speaking, it is the most likely image of a salmon you’ll find on the internet. But of course we know that this is not what was expected. And this is not just a bug. It’s a feature of AI.
I teach AI, I teach students how to program AI systems and machine learning systems. If I ask my students to come up with a program, without using machine learning or AI, that filters out the dogs from the cakes in these kind of images. It will be very difficult because it’s very hard to come up with a rule set that can discern A from B. At the same time, we know that for AI, machine learning, this is a very easy task. And that’s because the AI programs itself. Or in other words, AI can come up with a model that is so complex that we don’t understand how it works anymore, but it still produces the outcome that we’re looking for. In this case, a category classifier.
And that’s great because those very complex models allow us to build systems of infinite complexity. There’s no boundary to the complexity of the model. Just the data that you use, the computing power that you use, the fitness function that you use, but those things we can collect. But it’s also terrible because we don’t know how to deal with this complexity anymore. It’s beyond our human comprehension.
Now, about 12, 13 years ago, I was in Mountain View at Google. They had a self-driving car division. The head of their self-driving car division explains the following problem to us. He said: “We have to deal with all kinds of technical challenges. But what do you think our most difficult challenge is?” Now, this was a room full of engineers. So they said, “Well, the steering or locating yourself on the street or how do I do image segmentation?” He said, “No, you’re all wrong. Those are all technical problems that can be solved. There’s a much deeper underlying problem here. And that’s the problem of when do I break?”
Let’s say the camera spots something and there’s a 99% chance that it’s a leaf blowing by. And it’s a 1% chance that it’s a child crossing the street. Do you break? Well, of course, you would break in a 1% chance. But now we lower the chance to 0.1 or 0.01. At what point do you decide to break? The point, of course, is that we never make that decision as humans. But when you program a system like that, you have to make a decision because it’s rule-based. So you have to say if the probability is below this and that, then I break. So it becomes an ethical problem. And these kinds of ethical problems are much more difficult to solve than technological problems. Because who’s going to answer that? Who’s going to give you this number? It’s not the programmer. The programmer will go to the manager or to the CEO and they will go to the legal division or to the insurer or to the legislator. And nobody’s willing to provide an answer. For moral reasons, also for insurance reasons, it’s very difficult to solve this problem, he said. Now, nowadays they have a different approach. They just gather the data and they say based on this data, this is the probability of breaking that humans have. And so they moved the ethical challenge under the rug. But it’s still there. Don’t get fooled by those strategies.
The examples I showed, of Netflix and Google, are from tech companies. But you see it everywhere. We also know that AI is going to play a major role in healthcare in the future. Not just in medicine, but also in caring for the elderly, for monitoring, for prevention, etc. This raises lots of ethical questions. Is this desirable? Here we see a woman who needs care. There’s no care for her. This is from the documentary “Still Alice”. And there’s this robot companion taking care of her, mental care. Is this what we want or is this not what we want? Again, it’s not a technical question. It’s a moral question.
In the last 10, 15 years and in the foreseeable future, AI has moved from the lab to society. ChatGPT is adopted at a much higher rate than most companies know. A large percentage of employees use ChatGPT. But if you ask company CEOs, they probably mention a lower number because many employees use these kind of tools without the company knowing it. We know that a majority of jobs in the Netherlands will be affected by AI, either by full of partial displacement, or AI complementing their work. And we also know that there are enormous opportunities in terms of automation. So on the one hand, it’s very difficult to manage such technology, not just its bugs, but its intrinsic properties. On the other hand, it provides enormous promises for problems that we don’t know how else to solve.
So it’s wise to take a step back and think more deeply and more long-term about the effects of this technology – before we start thinking about how to innovate and how to regulate the technology. What helps us is looking back a little bit. There are other systems technologies like AI. We have the computer, we have the internet, we have the steam engine and electricity. And if you think about the steam engine, when it was first discovered, nobody had a clue of the implications of this technology 10, 20 or 30 years down the line. The first steam engines were used to automate factories. Instead of people working on benches close to each other so they could talk, the whole workforce was designed along the axis of this steam engine so everything would be mechanically automated. This meant a lot of changes to the workforce. It meant that work could go on hour after hour, even in the evenings and in the weekends because now you have this machine, and you want to keep using it. That led to societal changes. You had labor forces, you had unions, you had new ideologies popping up. The steam engine also became a lot smaller. You got the steam engine on railways. Railways meant completely different ways of warfare, economy, diplomacy. The world got a lot smaller. This all happened in the time span of several decades but we will see similar effects that are completely unpredictable as AI gets rolled out in the next couple of decades. Most of these effects of the steam engine were not technological. They were societal, economical, sometimes political. So it’s also good to be aware of this when it comes to AI.
A second element of AI is the speed at which it develops. I’ve been giving talks about artificial creativity for about 10 years now and 10, 8 years ago, it was very easy for me to create a talk. I could just show people this image and then I would say, this cat does not exist and people would be taken aback. This was the highlight of my presentation. Now I show you this image and nobody raises an eyebrow. And then two years later, I had to show this image. Again, I see no reaction from you. I don’t expect any reaction, by the way. But it shows just how fast it goes and how quickly we adopt and get used to these kind of tools. And it also raises the question: given what was achieved in the past 8 years, where will we be in 25 years from now? You can, of course, apply AI in completely new different fields, similar as was done with the steam engine: creating new materials, coming up with new inventions, new types of engineering. We already know that AI has a major role to play in creativity and in coding.
We also know that the AI that we know now is very primitive. I’ll be giving another speech in 10 years and the audience won’t be taken aback by anything. Because what we see today is AI with a very old interface. At ChatGPT, it’s the interface of the internet [i.e. a text command prompt], of the previous system technology. And that’s always been the case. When the first car was invented, it was a horseless carriage. When the first TV was invented, it was essentially radio programming with an image added to it. And now what we have with AI is an internet browser with an AI model behind it. And for most of you who have been following the news, you see that the interfaces are developing very rapidly. You’ll get voice interfaces, you’ll get a lot more personalization with AI. This is also a trend that’s very clear.
So we talked a bit about the history, we talked a bit about the pace of development, about the complexity being a feature, not a bug. We can also dive a little bit more into the technology itself. This is a graph I designed five years ago with a student of mine. It’s called the Neural Network Zoo. And what you see is from the top left, all the way to the bottom right, is the evolution of neural network architectures. Interestingly, at the bottom right, this is called the transformer architecture. Essentially, the evolution stopped and most AI that you hear about nowadays, most AI developed at Microsoft and Google and OpenAI and others are based on this transformer architecture. So there was this Cambrian explosion of architectures, and then suddenly it converged.
Until five years or so AI models were proliferating. Now they’re also converging. Nowadays, we talk about OpenAI’s GPT, we talk about Google’s Gemini, we talk about Meta’s LAMA, Mistral. There aren’t that many models. So not just the technology has been locking in, but the models themselves as well. So you see huge conversions into only a very limited set of players and models. And this is of course due to the scaling laws. It becomes very difficult to play in this game. But it’s very interesting that on the one hand you have a convergence to a limited set of models in a limited set of companies. And on the other hand, you have this emergence of new functionalities coming out of these large scale models. So they surprise us all the time, but they’re only a very limited set of models that are able to surprise us. And these developments, these trends, all inform the way that we regulate this technology.
This is currently how the European Union thinks about regulating this technology. You have four categories. (1) A minimal risk category where there’s not much or hardly any legislation. (2) A limited risk. For example, if I interact with a chatbot, I have to know I’m interacting with a chatbot and not a human. The AI has to be transparent. (3) A high risk category, where there will be all kinds of ethical checks around, let’s say toys or healthcare or anything that has a real risk for consumers or citizens or society. (4) Unacceptable risk, which is AI systems that can subconsciously influence you, do social scoring, etc. Those will all be forbidden under new legislation (the EU AI Act).
I’ll end the presentation with this final quote, because I think this is essentially where we are right now: “The real problem of humanity is the following: we have paleolithic emotions, medieval institutions and with AI, god-like technology.” (E.O. Wilson).
The 2024 Nobel Prizes in Physics and Chemistry put the spotlight on AI. While the Physics laureates, John Hopfield and Geoffrey Hinton, contributed to its theoretical foundations, two of the three Chemistry laureates – specifically, Demis Hassabis and John Jumper – were rewarded for putting it into use.
John Hopfield developed the Hopfield network in 1982, a form of recurrent artificial neural network that can store and retrieve patterns, mimicking how human memory works. It operates by processing and recognizing patterns even when presented with incomplete or distorted data. His work was significant because it helped bridge the gap between biology and computer science, showing how computational systems could simulate the way the human brain stores and retrieves information.
Geoffrey Hinton co-invented the Boltzmann Machines, a type of neural network that played an important role in understanding how networks can be trained to discover patterns in data. He also popularized the use of backpropagation, an algorithm for training multi-layer neural networks, which considerably improved their capacity to learn complex patterns. Hinton’s contributions ultimately led to AI systems like GPT (Generative Pre-trained Transformers), which underpins ChatGPT, and AlphaFold the AI program that earned Demis Hassabis and John Jumper their Nobel prize in Chemistry.
AlphaFold solved one of biology’s greatest challenges: accurately predicting the 3D structure of proteins from their amino acid sequences. This problem had stumped scientists for decades, as protein folding is essential to understanding how proteins function, which is crucial for drug discovery, disease research, and biotechnology. AlphaFold’s predictions were so accurate that they matched experimental results with near-perfect precision, revolutionizing the field of biology. This breakthrough has wide-ranging implications for medicine and has already begun to accelerate research into diseases, drug discovery, and bioengineering.
Creating a blueprint for AI Transformation
Our strategies elevate the performance of your AI applications from marginal or tactical results to unequivocal, transformational successes.
Discover our Data & AI StrategyTowards AI-driven disruption of traditional business models
Beyond the world of academia and frontier research, the AI techniques developed by the 2024 laureates are permeating the business world too. For one, the capabilities to analyse, identify patterns, and make sense of vast datasets, particularly unstructured data, rely at least partially on them.
From supply chain optimization to consumer behaviour analysis, AI holds the promise of making data-driven decisions faster, and automating a growing range of tasks. Large companies have already launched initiatives to capitalize on this, with some notable successes. Witness the case of a telecom company that generated an ROI 2.5x higher than average thanks to the judicious use of AI; or the case of an energy provider that delivered savings for consumers while increasing its own revenues; or this Supply Chain example that minimized waste and lost sales, while reducing the need for manual intervention at store level. These cases are no exceptions. Increasingly, the deployment of advanced algorithms and data management techniques play a central role in gaining competitive advantage.
Ultimately, AI ability to make sense of vast quantities of data will accelerate innovation and paves the way for new business models that will disrupt existing ones. From biotech to finance and manufacturing, the possibilities are endless, and all industries will eventually be impacted. More prosaically, the breakthroughs of the 2024 Nobel laureates herald an era when AI is not just a futuristic concept, but a key driver of competitiveness right now.