Blog
Key points from a webinar on grounding and governing AI agents at scale.

Many companies can come up with an AI agent demo. Fewer can put it in production.
In conversations with senior leaders at companies across a range of industries – from finance to retail and industrial manufacturing - we keep hearing a version of the same frustration: the demos work brilliantly, the stakeholders are excited, and then something stalls on the way to scale. But the agents behave strangely in edge cases. Governance becomes a bottleneck. Maintenance costs balloon as each new use case requires its own bespoke configuration.
We ran a webinar recently to dig into exactly this challenge. What follows are the core ideas from that session and our view on what enterprises need to do differently if they are serious about deploying agentic AI at scale.
Confidence is rising faster than readiness
With today’s front-end tooling and LLM capabilities, almost any team can produce something that looks impressive in a meeting room. That is genuinely useful: it generates buy-in, surfaces requirements, and tests appetite. But it creates a dangerous illusion: that scaling will be just as easy.
It isn’t.
The hard part is industrialisation. Specifically, it comes down to two challenges that most enterprises are not yet solving at the level they need to:
- Grounding agents by giving them the right context to reason reliably on company-specific knowledge
- Governance guardrails that ensure that agents act within defined boundaries, with full traceability of what they did and why
Both are solvable. But solving them at scale requires a fundamentally different approach than what most teams are currently taking.
Why system prompting doesn’t scale
When organisations build their first agent, they typically invest heavily in the system prompt. They write down the agent’s role, its constraints, company-specific policies, definitions, access rules — sometimes running to tens of pages of YAML configuration. It works, for that agent.
Then they build a second agent. And a third. Each one gets its own bespoke prompt, its own embedded knowledge, its own version of the truth.
Think of it this way: imagine you needed to onboard 500 new employees every Monday. Would you rewrite the onboarding manual from scratch for each one? Of course not — you would create one set of materials that captures how the company works, and distribute it consistently. The same logic applies to agents. Once you are running not five but fifty or five hundred specialised agents — which is where the leading organisations are heading — the per-agent system-prompting model collapses under its own weight. It’s inefficient, inconsistent, and almost impossible to keep current as policies evolve.
The alternative is to treat company knowledge as a shared, governed asset that agents draw from at runtime — rather than knowledge that gets duplicated and embedded inside each individual agent.
The knowledge graph as a thin, navigable layer
This is where graph-based knowledge systems come in. Not as a data migration project, and not as a replacement for your existing data stack — but as a thin contextual layer that sits above it.
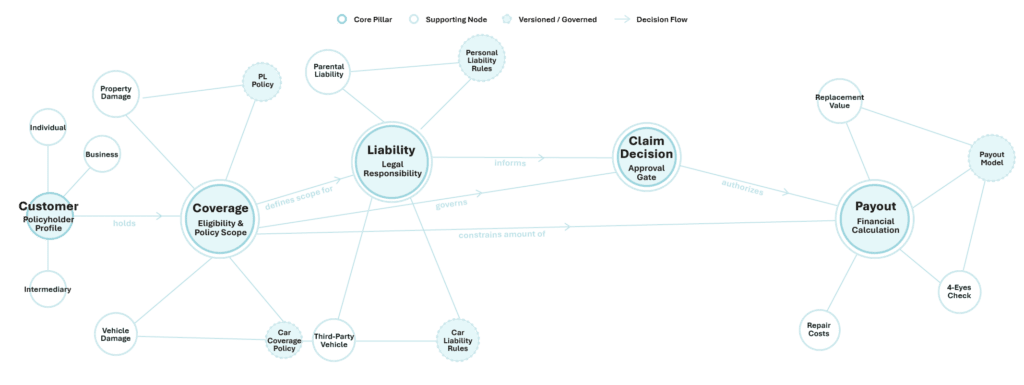
In a demo we built for the insurance sector, we showed two very different claim types — a car insurance claim and a personal liability claim — both reasoning over the same underlying knowledge graph. The graph itself does not store vast amounts of data. It stores the relationships between concepts: coverage, liability, payout thresholds, policy versions, ownership. When a claim arrives, the agent traverses the graph to identify which nodes are relevant, then fetches the underlying data from wherever it actually lives.
The result is a system where shared knowledge is defined once, versioned, governed, and reused across use cases. When a policy changes, you update it in one place. Every agent that depends on that policy gets the updated version automatically.
Governance is not optional infrastructure
Governance is where most agentic AI initiatives will either compound or collapse.
The governance question for agents is essentially: who said what, why, and were they even allowed to? Without clear answers to those questions at every step, you are not running a governed system — you are running a risk.
There are two dimensions worth separating here.
- Access management becomes your decision boundary. Traditional identity and access management was a back-end control layer — who can log in, who can view which reports. In an agentic enterprise, it becomes something more active: the mechanism that determines, in real time, whether an agent is authorised to take a specific action on a specific piece of data. In our insurance demo, a claim below a certain payout threshold could be approved automatically. One above that threshold triggered a human-in-the-loop approval flow — and critically, the two approvers were granted access to only the specific documents and context needed for that decision, only for the duration of that approval. Access on the fly, not standing access. That distinction matters enormously as agents begin acting on behalf of humans at scale.
- Audit trails are not just a compliance requirement — they are the foundation for improving the system. When an agent makes a decision you didn’t expect, you need to be able to trace back exactly what knowledge it drew on, which version of which policy it referenced, what reasoning it applied, and what human actions (if any) were taken. Without that traceability, you cannot distinguish between a bad policy, a bad prompt, and a bad decision by a human approver. With it, you can close the loop.
You are not starting from zero
One of the most important points we want to make is this: the road to governed, grounded agentic AI is not greenfield.
Most enterprises we work with have spent the last several years doing the work of data management — data products, data contracts, data mesh thinking, semantic alignment across source systems. That work is not wasted. It is, in fact, the foundation. Raw data, once structured and contextualised, becomes information. Information, connected across domains in graph-like structures, becomes knowledge. And knowledge, made available to agents at runtime, is what enables them to reason reliably.
Five principles for getting governance right from the start
Based on what we have seen work — and what we have seen fail — we offer five principles for building knowledge governance into your agentic systems from day one.
1. Govern knowledge, not just data. Data governance covers facts. Knowledge governance covers meaning, rules, and provenance. Both need to be explicit, structured, and traceable. If your agents rely on knowledge that can change without a formal update pipeline, the system is only as reliable as its weakest human process.
2. Design for both humans and machines. Every interface, standard, and format you adopt should be interpretable by both. We strongly favour human-machine-readable formats such as YAML precisely because they create a single source of truth that both can rely on.
3. Build knowledge as an enterprise layer, not an application layer. The temptation, especially early, is to embed knowledge directly into the application you are building. Resist it. If you store semantic definitions in four different application-specific layers, you have four copies of the truth, and coordination costs that grow with each new use case.
4. Make governance the fastest path to production, not the slowest. Governance has a reputation for slowing things down. That reputation is often earned — but it does not have to be. If the governance mechanisms are cumbersome, engineering teams will route around them. Design for speed and compliance simultaneously, and adoption follows naturally.
5. Build the audit trail first. Traceability is not something to retrofit. The moment you have a full audit trail of agent reasoning, knowledge versions, access decisions, and human approvals, you have the feedback loop that allows the system to improve. Without it, every incident is a black box.
What this means for you, today
Agentic AI is no longer hypothetical. Major enterprises across insurance, telecom, retail, and manufacturing are already running agentic systems in production. The organisations that will move fastest are not those with the biggest models — they are those with the most codified, governed, reusable knowledge.
The competitive advantage is not the agent. It is the knowledge the agent can reliably draw on.
This webinar and article were produced by Rewire's Helen Rijkes (Partner), Freek Gulden (Principal), Nanne van 't Klooster (Principal), and Job van Zijl (Senior Data engineer).
Building your AI capabilities, end-to-end
Our strategies elevate the impact of AI from marginal or tactical to transformational successes.
Explore our AI services


